 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Inductive Biases for Factorial Representation-Learning
Paper and Code
Dec 15, 2016

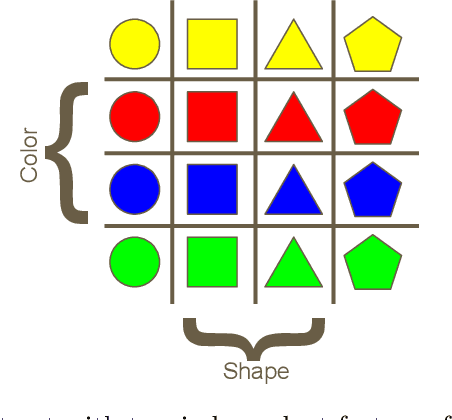
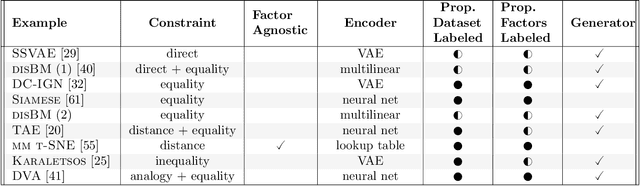
With the resurgence of interest in neural networks, representation learning has re-emerged as a central focus in artificial intelligence. Representation learning refers to the discovery of useful encodings of data that make domain-relevant information explicit. Factorial representations identify underlying independent causal factors of variation in data. A factorial representation is compact and faithful, makes the causal factors explicit, and facilitates human interpretation of data. Factorial representations support a variety of applications, including the generation of novel examples, indexing and search, novelty detection, and transfer learning. This article surveys various constraints that encourage a learning algorithm to discover factorial representations. I dichotomize the constraints in terms of unsupervised and supervised inductive bias. Unsupervised inductive biases exploit assumptions about the environment, such as the statistical distribution of factor coefficients, assumptions about the perturbations a factor should be invariant to (e.g. a representation of an object can be invariant to rotation, translation or scaling), and assumptions about how factors are combined to synthesize an observation. Supervised inductive biases are constraints on the representations based on additional information connected to observations. Supervisory labels come in variety of types, which vary in how strongly they constrain the representation, how many factors are labeled, how many observations are labeled, and whether or not we know the associations between the constraints and the factors they are related to. This survey brings together a wide variety of models that all touch on the problem of learning factorial representations and lays out a framework for comparing these models based on the strengths of the underlying supervised and unsupervised inductive biases.