 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Self-Supervised Pretraining for Vision Problems in Gastrointestinal Endoscopy
Paper and Code
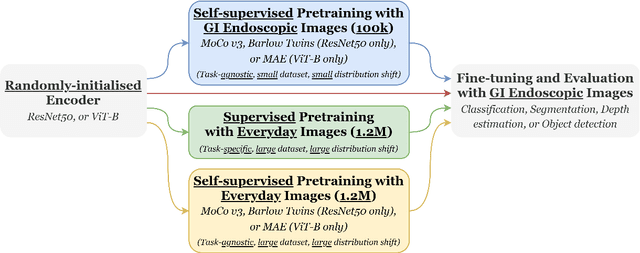
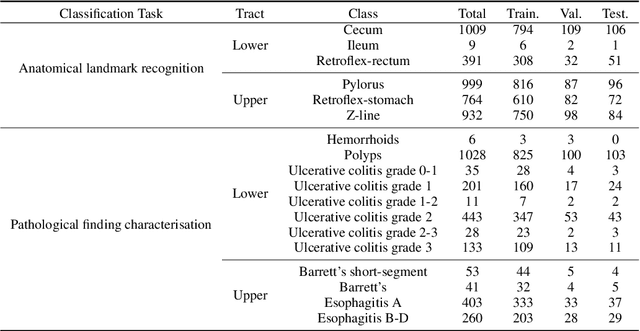
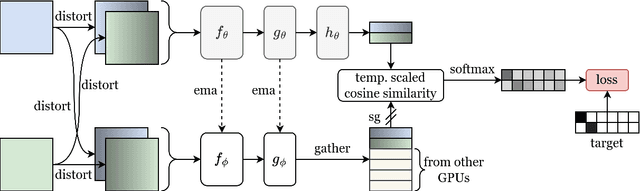

Solutions to vision tasks in gastrointestinal endoscopy (GIE) conventionally use image encoders pretrained in a supervised manner with ImageNet-1k as backbones. However, the use of modern self-supervised pretraining algorithms and a recent dataset of 100k unlabelled GIE images (Hyperkvasir-unlabelled) may allow for improvements. In this work, we study the fine-tuned performance of models with ResNet50 and ViT-B backbones pretrained in self-supervised and supervised manners with ImageNet-1k and Hyperkvasir-unlabelled (self-supervised only) in a range of GIE vision tasks. In addition to identifying the most suitable pretraining pipeline and backbone architecture for each task, out of those considered, our results suggest: that self-supervised pretraining generally produces more suitable backbones for GIE vision tasks than supervised pretraining; that self-supervised pretraining with ImageNet-1k is typically more suitable than pretraining with Hyperkvasir-unlabelled, with the notable exception of monocular depth estimation in colonoscopy; and that ViT-Bs are more suitable in polyp segmentation and monocular depth estimation in colonoscopy, ResNet50s are more suitable in polyp detection, and both architectures perform similarly in anatomical landmark recognition and pathological finding characterisation. We hope this work draws attention to the complexity of pretraining for GIE vision tasks, informs this development of more suitable approaches than the convention, and inspires further research on this topic to help advance this development. Code available: \underline{github.com/ESandML/SSL4GIE}