 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Transfer Learning in Music Source Separation
Paper and Code
Oct 23, 2020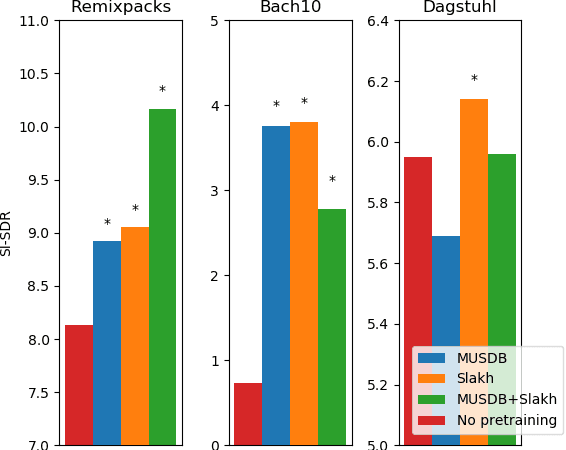
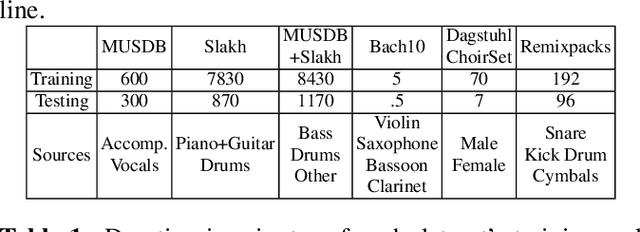
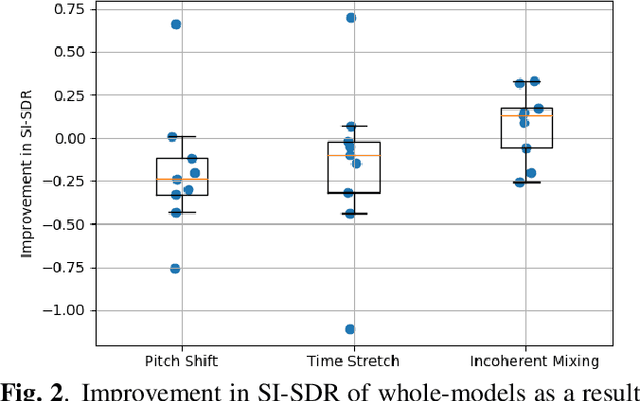

Supervised deep learning methods for performing audio source separation can be very effective in domains where there is a large amount of training data. While some music domains have enough data suitable for training a separation system, such as rock and pop genres, many musical domains do not, such as classical music, choral music, and non-Western music traditions. It is well known that transferring learning from related domains can result in a performance boost for deep learning systems, but it is not always clear how best to do pretraining. In this work we investigate the effectiveness of data augmentation during pretraining, the impact on performance as a result of pretraining and downstream datasets having similar content domains, and also explore how much of a model must be retrained on the final target task, once pretrained.