 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study in Rashomon curves and volumes: A new perspective on generalization and model simplicity in machine learning
Paper and Code
Aug 05, 2019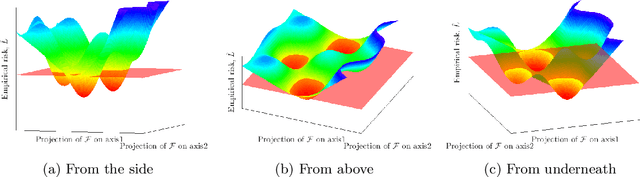


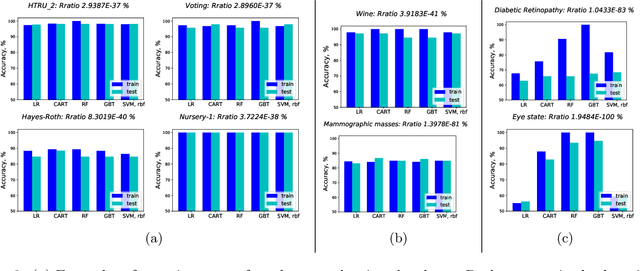
The Rashomon effect occurs when many different explanations exist for the same phenomenon. In machine learning, Leo Breiman used this term to describe problems where many accurate-but-different models exist to describe the same data. In this work, we study how the Rashomon effect can be useful for understanding the relationship between training and test performance, and the possibility that simple-yet-accurate models exist for many problems. We introduce the Rashomon set as the set of almost-equally-accurate models for a given problem, and study its properties and the types of models it could contain. We present the Rashomon ratio as a new measure related to simplicity of model classes, which is the ratio of the volume of the set of accurate models to the volume of the hypothesis space; the Rashomon ratio is different from standard complexity measures from statistical learning theory. For a hierarchy of hypothesis spaces, the Rashomon ratio can help modelers to navigate the trade-off between simplicity and accuracy in a surprising way. In particular, we find empirically that a plot of empirical risk vs. Rashomon ratio forms a characteristic $\Gamma$-shaped Rashomon curve, whose elbow seems to be a reliable model selection criterion. When the Rashomon set is large, models that are accurate - but that also have various other useful properties - can often be obtained. These models might obey various constraints such as interpretability, fairness, monotonicity, and computational benefits.