 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistically Principled and Computationally Efficient Approach to Speech Enhancement using Variational Autoencoders
Paper and Code
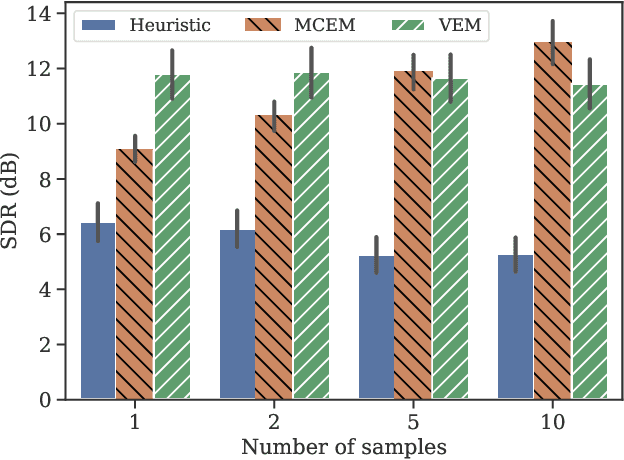

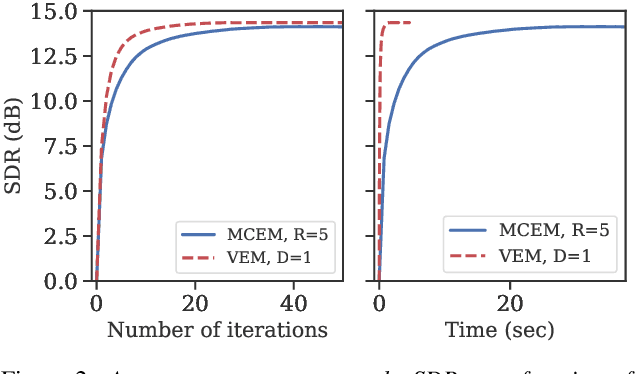
Recent studies have explored the use of deep generative models of speech spectra based of variational autoencoders (VAEs), combined with unsupervised noise models, to perform speech enhancement. These studies developed iterative algorithms involving either Gibbs sampling or gradient descent at each step, making them computationally expensive. This paper proposes a variational inference method to iteratively estimate the power spectrogram of the clean speech. Our main contribution is the analytical derivation of the variational steps in which the en-coder of the pre-learned VAE can be used to estimate the varia-tional approximation of the true posterior distribution, using the very same assumption made to train VAEs. Experiments show that the proposed method produces results on par with the afore-mentioned iterative methods using sampling, while decreasing the computational cost by a factor 36 to reach a given performance .