 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spiking Neural Network Learning Markov Chain
Paper and Code
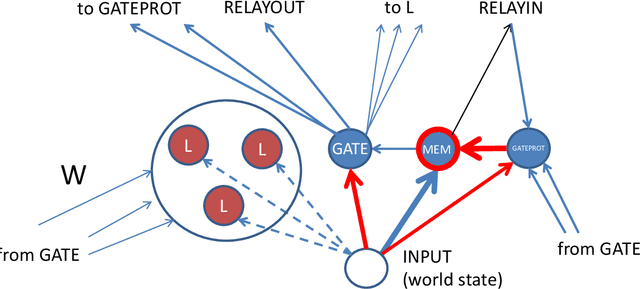
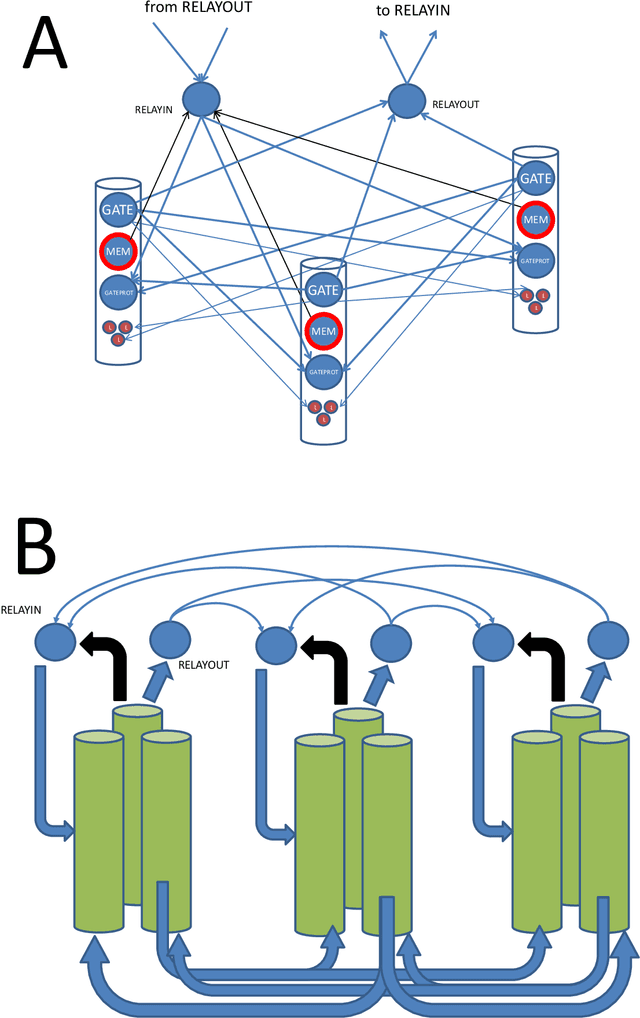
In this paper, the question how spiking neural network (SNN) learns and fixes in its internal structures a model of external world dynamics is explored. This question is important for implementation of the model-based reinforcement learning (RL), the realistic RL regime where the decisions made by SNN and their evaluation in terms of reward/punishment signals may be separated by significant time interval and sequence of intermediate evaluation-neutral world states. In the present work, I formalize world dynamics as a Markov chain with unknown a priori state transition probabilities, which should be learnt by the network. To make this problem formulation more realistic, I solve it in continuous time, so that duration of every state in the Markov chain may be different and is unknown. It is demonstrated how this task can be accomplished by an SNN with specially designed structure and local synaptic plasticity rules. As an example, we show how this network motif works in the simple but non-trivial world where a ball moves inside a square box and bounces from its walls with a random new direction and velocity.