 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Optimal Policy Design for Online Learning with Safety against Heavy-tailed Risk
Paper and Code
Jun 07, 2022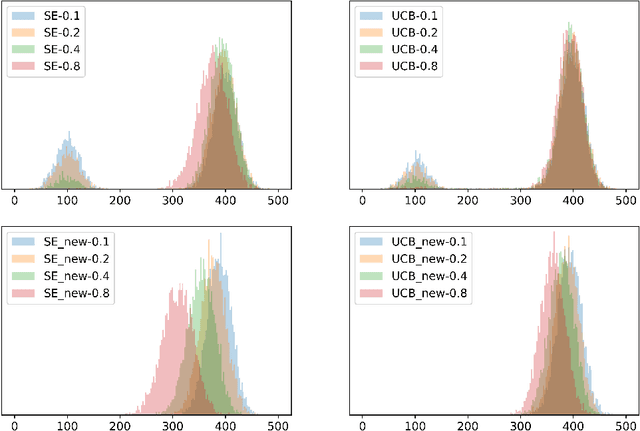
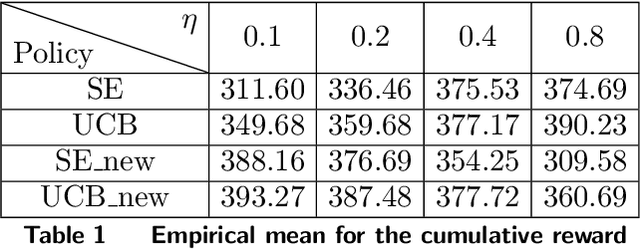
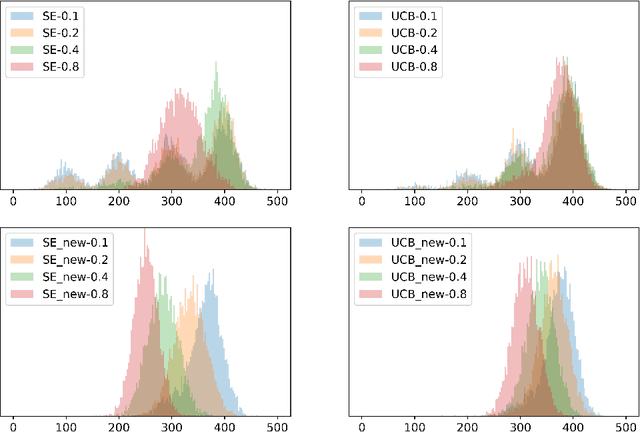
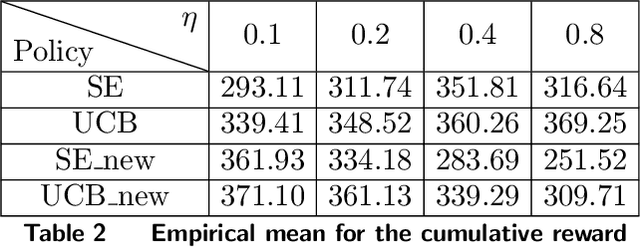
We design simple and optimal policies that ensure safety against heavy-tailed risk in the classical multi-armed bandit problem. We start by showing that some widely used policies such as the standard Upper Confidence Bound policy and the Thompson Sampling policy incur heavy-tailed risk; that is, the worst-case probability of incurring a linear regret slowly decays at a polynomial rate of $1/T$, where $T$ is the time horizon. We further show that this heavy-tailed risk exists for all "instance-dependent consistent" policies. To ensure safety against such heavy-tailed risk, for the two-armed bandit setting, we provide a simple policy design that (i) has the worst-case optimality for the expected regret at order $\tilde O(\sqrt{T})$ and (ii) has the worst-case tail probability of incurring a linear regret decay at an exponential rate $\exp(-\Omega(\sqrt{T}))$. We further prove that this exponential decaying rate of the tail probability is optimal across all policies that have worst-case optimality for the expected regret. Finally, we improve the policy design and analysis to the general $K$-armed bandit setting. We provide detailed characterization of the tail probability bound for any regret threshold under our policy design. Namely, the worst-case probability of incurring a regret larger than $x$ is upper bounded by $\exp(-\Omega(x/\sqrt{KT}))$. Numerical experiments are conducted to illustrate the theoretical findings. Our results reveal insights on the incompatibility between consistency and light-tailed risk, whereas indicate that worst-case optimality on expected regret and light-tailed risk are compatible.