 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Short Survey on Data Clustering Algorithms
Paper and Code
Nov 25, 2015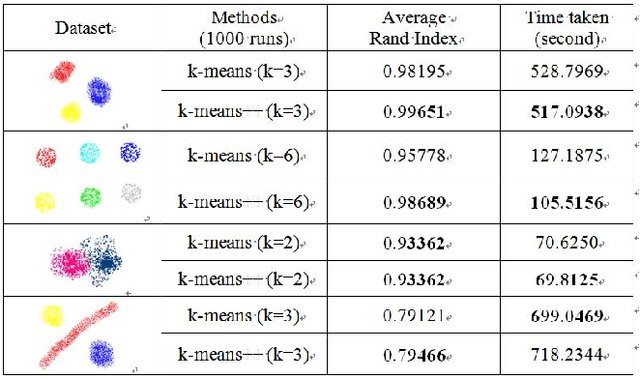
With rapidly increasing data, clustering algorithms are important tools for data analytics in modern research. They have been successfully applied to a wide range of domains; for instance, bioinformatics, speech recognition, and financial analysis. Formally speaking, given a set of data instances, a clustering algorithm is expected to divide the set of data instances into the subsets which maximize the intra-subset similarity and inter-subset dissimilarity, where a similarity measure is defined beforehand. In this work, the state-of-the-arts clustering algorithms are reviewed from design concept to methodology; Different clustering paradigms are discussed. Advanced clustering algorithms are also discussed. After that, the existing clustering evaluation metrics are reviewed. A summary with future insights is provided at the end.