 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Speaker Clustering Method Based on Discrete Tied Variational Autoencoder
Paper and Code
Mar 04, 2020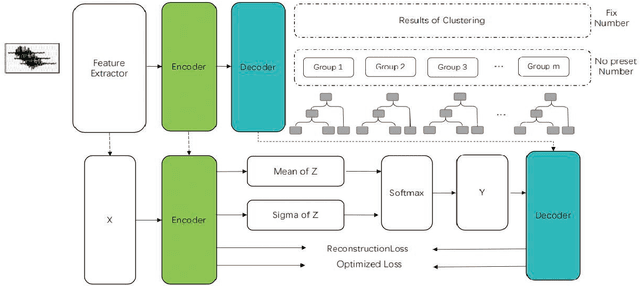
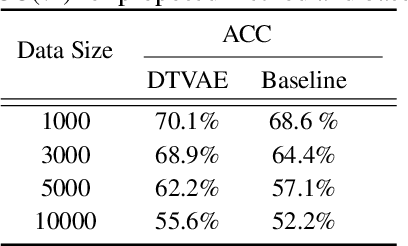
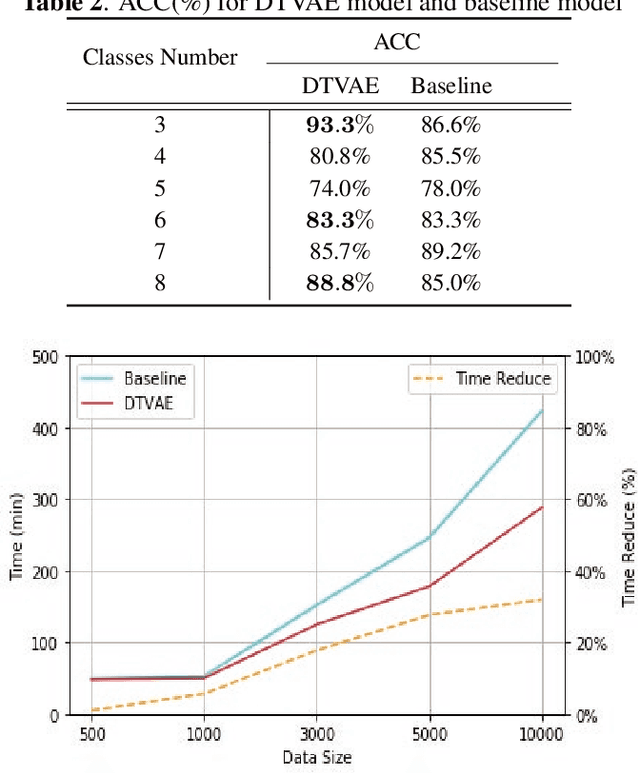
Recently, the speaker clustering model based on aggregation hierarchy cluster (AHC) is a common method to solve two main problems: no preset category number clustering and fix category number clustering. In general, model takes features like i-vectors as input of probability and linear discriminant analysis model (PLDA) aims to form the distance matric in long voice application scenario, and then clustering results are obtained through the clustering model. However, traditional speaker clustering method based on AHC has the shortcomings of long-time running and remains sensitive to environment noise. In this paper, we propose a novel speaker clustering method based on Mutual Information (MI) and a non-linear model with discrete variable, which under the enlightenment of Tied Variational Autoencoder (TVAE), to enhance the robustness against noise. The proposed method named Discrete Tied Variational Autoencoder (DTVAE) which shortens the elapsed time substantially. With experience results, it outperforms the general model and yields a relative Accuracy (ACC) improvement and significant time reduction.