 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random-Feature Based Newton Method for Empirical Risk Minimization in Reproducing Kernel Hilbert Space
Paper and Code
Feb 16, 2020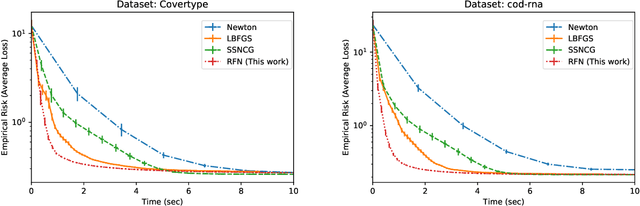
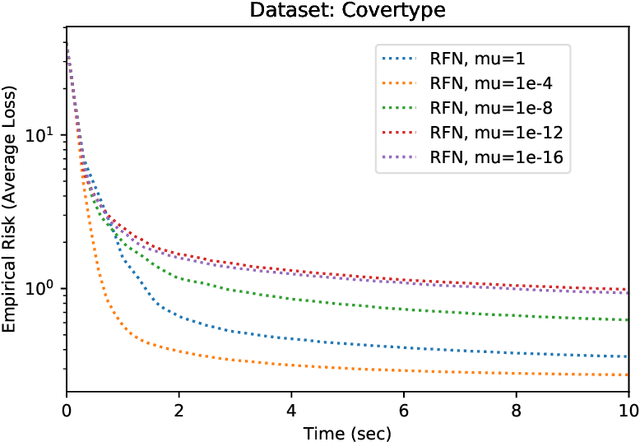

In supervised learning using kernel methods, we encounter a large-scale finite-sum minimization over a reproducing kernel Hilbert space(RKHS). Often times large-scale finite-sum problems can be solved using efficient variants of Newton's method where the Hessian is approximated via sub-samples. In RKHS, however, the dependence of the penalty function to kernel makes standard sub-sampling approaches inapplicable, since the gram matrix is not readily available in a low-rank form. In this paper, we observe that for this class of problems, one can naturally use kernel approximation to speed up the Newton's method. Focusing on randomized features for kernel approximation, we provide a novel second-order algorithm that enjoys local superlinear convergence and global convergence in the high probability sense. The key to our analysis is showing that the approximated Hessian via random features preserves the spectrum of the original Hessian. We provide numerical experiments verifying the efficiency of our approach, compared to variants of sub-sampling methods.