 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proposal to Study "Is High Quality Data All We Need?"
Paper and Code
Mar 12, 2022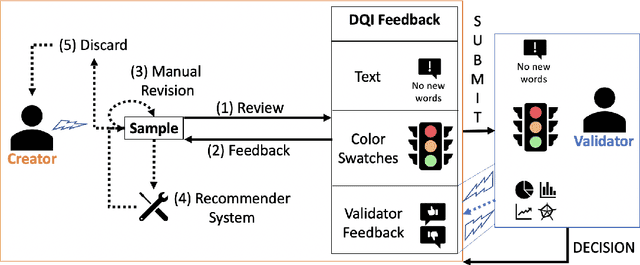

Even though deep neural models have achieved superhuman performance on many popular benchmarks, they have failed to generalize to OOD or adversarial datasets. Conventional approaches aimed at increasing robustness include developing increasingly large models and augmentation with large scale datasets. However, orthogonal to these trends, we hypothesize that a smaller, high quality dataset is what we need. Our hypothesis is based on the fact that deep neural networks are data driven models, and data is what leads/misleads models. In this work, we propose an empirical study that examines how to select a subset of and/or create high quality benchmark data, for a model to learn effectively. We seek to answer if big datasets are truly needed to learn a task, and whether a smaller subset of high quality data can replace big datasets. We plan to investigate both data pruning and data creation paradigms to generate high quality datasets.