 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Perspective on Large Language Models, Intelligent Machines, and Knowledge Acquisition
Paper and Code
Aug 13, 2024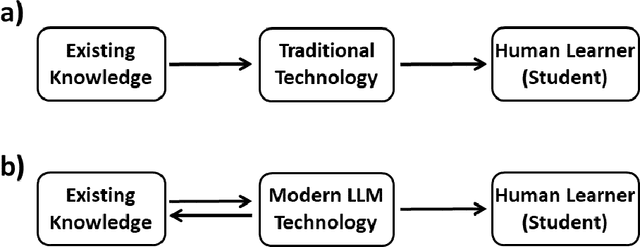
Large Language Models (LLMs) are known for their remarkable ability to generate synthesized 'knowledge', such as text documents, music, images, etc. However, there is a huge gap between LLM's and human capabilities for understanding abstract concepts and reasoning. We discuss these issues in a larger philosophical context of human knowledge acquisition and the Turing test. In addition, we illustrate the limitations of LLMs by analyzing GPT-4 responses to questions ranging from science and math to common sense reasoning. These examples show that GPT-4 can often imitate human reasoning, even though it lacks understanding. However, LLM responses are synthesized from a large LLM model trained on all available data. In contrast, human understanding is based on a small number of abstract concepts. Based on this distinction, we discuss the impact of LLMs on acquisition of human knowledge and education.