 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Peek Into the Hidden Layers of a Convolutional Neural Network Through a Factorization Lens
Paper and Code
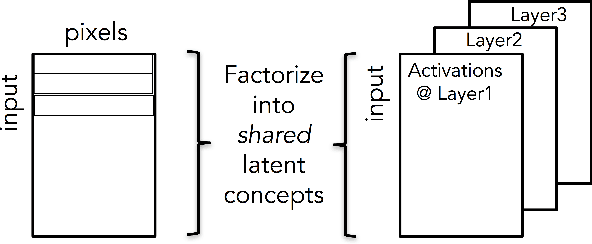

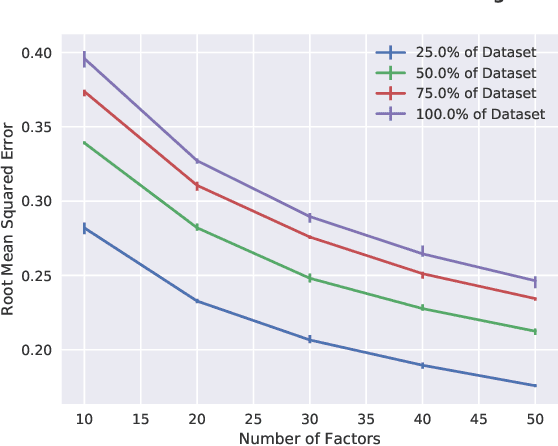
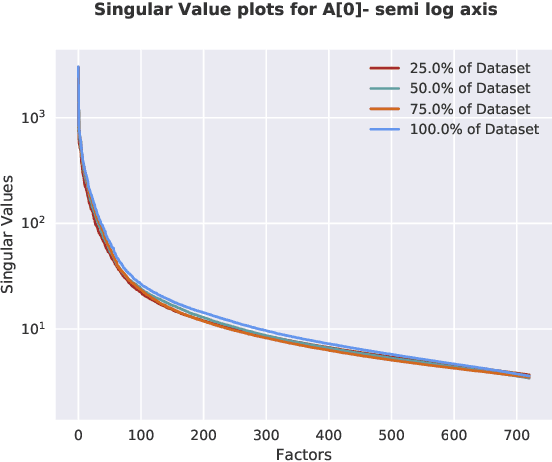
Despite their increasing popularity and success in a variety of supervised learning problems, deep neural networks are extremely hard to interpret and debug: Given and already trained Deep Neural Net, and a set of test inputs, how can we gain insight into how those inputs interact with different layers of the neural network? Furthermore, can we characterize a given deep neural network based on it's observed behavior on different inputs? In this paper we propose a novel factorization based approach on understanding how different deep neural networks operate. In our preliminary results, we identify fascinating patterns that link the factorization rank (typically used as a measure of interestingness in unsupervised data analysis) with how well or poorly the deep network has been trained. Finally, our proposed approach can help provide visual insights on how high-level. interpretable patterns of the network's input behave inside the hidden layers of the deep network.