 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Paradoxical Property of the Monkey Book
Paper and Code
Mar 14, 2011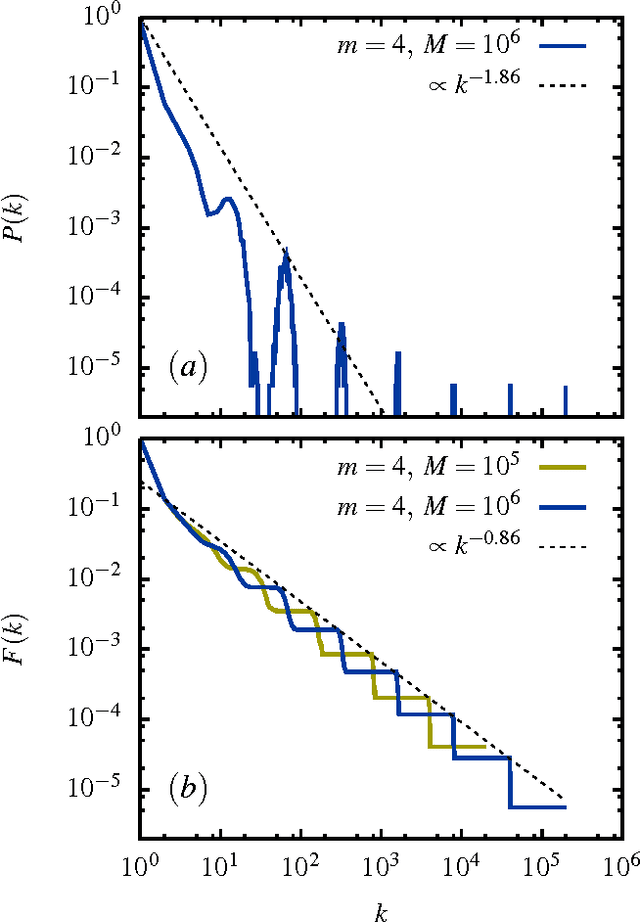
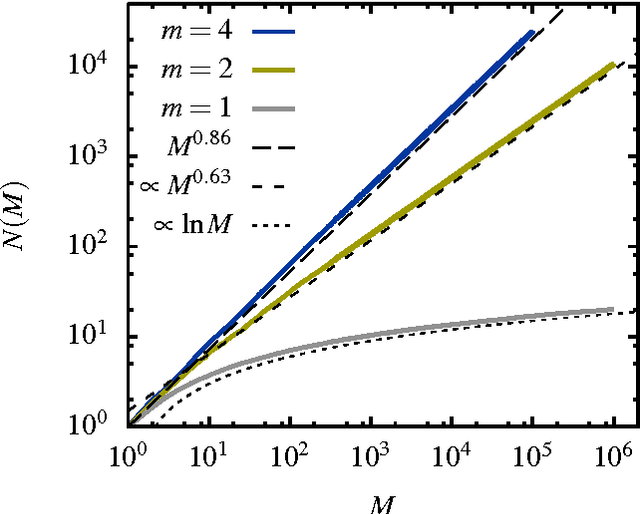
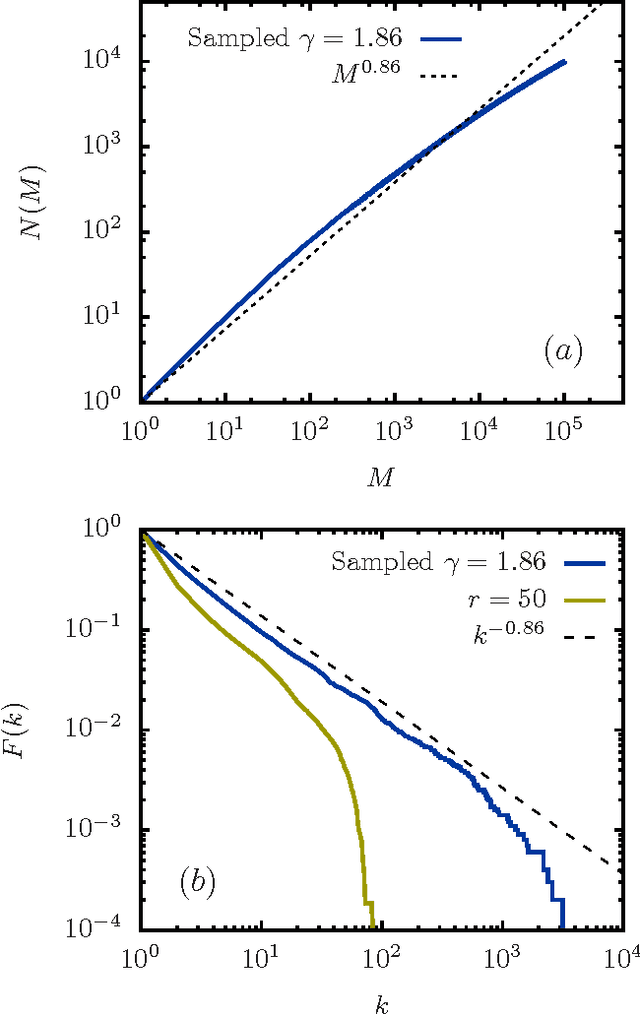
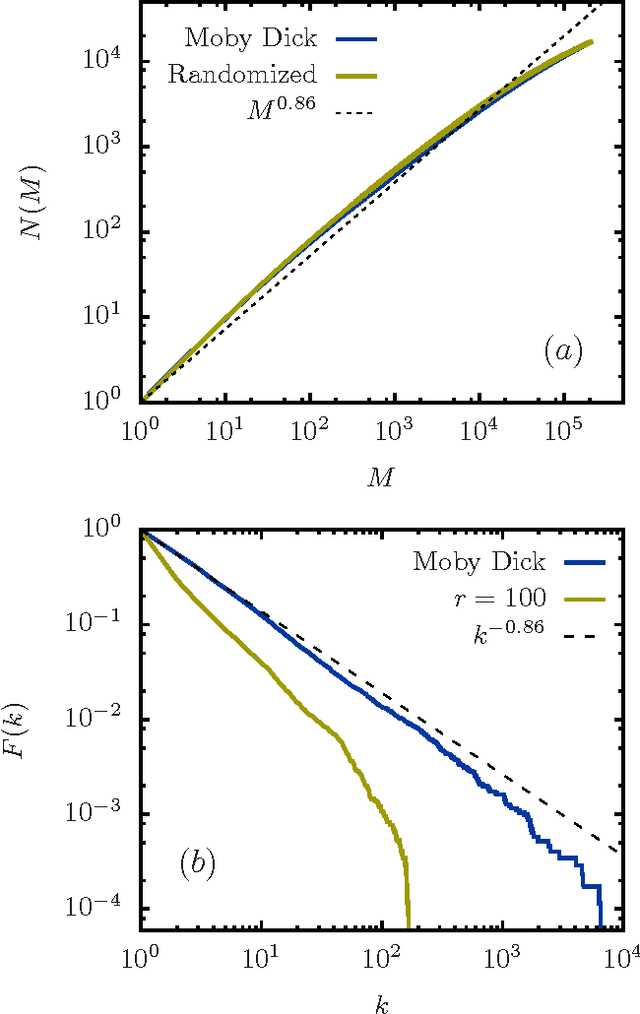
A "monkey book" is a book consisting of a random distribution of letters and blanks, where a group of letters surrounded by two blanks is defined as a word. We compare the statistics of the word distribution for a monkey book with the corresponding distribution for the general class of random books, where the latter are books for which the words are randomly distributed. It is shown that the word distribution statistics for the monkey book is different and quite distinct from a typical sampled book or real book. In particular the monkey book obeys Heaps' power law to an extraordinary good approximation, in contrast to the word distributions for sampled and real books, which deviate from Heaps' law in a characteristics way. The somewhat counter-intuitive conclusion is that a "monkey book" obeys Heaps' power law precisely because its word-frequency distribution is not a smooth power law, contrary to the expectation based on simple mathematical arguments that if one is a power law, so is the other.