Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA PAC-Bayesian Analysis of Randomized Learning with Application to Stochastic Gradient Descent
Paper and Code
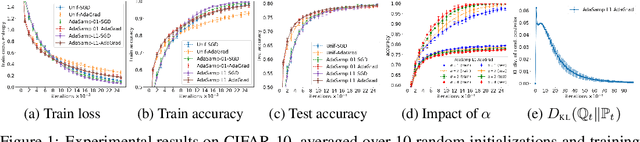
We study the generalization error of randomized learning algorithms -- focusing on stochastic gradient descent (SGD) -- using a novel combination of PAC-Bayes and algorithmic stability. Importantly, our generalization bounds hold for all posterior distributions on an algorithm's random hyperparameters, including distributions that depend on the training data. This inspires an adaptive sampling algorithm for SGD that optimizes the posterior at runtime. We analyze this algorithm in the context of our generalization bounds and evaluate it on a benchmark dataset. Our experiments demonstrate that adaptive sampling can reduce empirical risk faster than uniform sampling while also improving out-of-sample accuracy.
* In Neural Information Processing Systems (NIPS) 2017
View paper on