 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Intrinsic Measure of Data Separability
Paper and Code
Sep 11, 2021

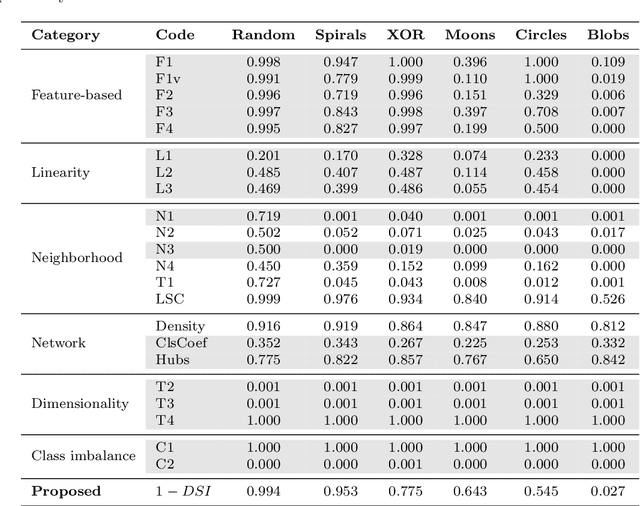
In machine learning, the performance of a classifier depends on both the classifier model and the separability/complexity of datasets. To quantitatively measure the separability of datasets, we create an intrinsic measure -- the Distance-based Separability Index (DSI), which is independent of the classifier model. We consider the situation in which different classes of data are mixed in the same distribution to be the most difficult for classifiers to separate. We then formally show that the DSI can indicate whether the distributions of datasets are identical for any dimensionality. And we verify the DSI to be an effective separability measure by comparing to several state-of-the-art separability/complexity measures using synthetic and real datasets. Having demonstrated the DSI's ability to compare distributions of samples, we also discuss some of its other promising applications, such as measuring the performance of generative adversarial networks (GANs) and evaluating the results of clustering methods.