 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Note on Lazy Training in Supervised Differentiable Programming
Paper and Code



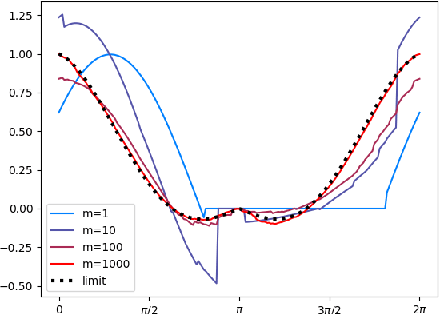
In a series of recent theoretical works, it has been shown that strongly over-parameterized neural networks trained with gradient-based methods could converge linearly to zero training loss, with their parameters hardly varying. In this note, our goal is to exhibit the simple structure that is behind these results. In a simplified setting, we prove that "lazy training" essentially solves a kernel regression. We also show that this behavior is not so much due to over-parameterization than to a choice of scaling, often implicit, that allows to linearize the model around its initialization. These theoretical results complemented with simple numerical experiments make it seem unlikely that "lazy training" is behind the many successes of neural networks in high dimensional tasks.