Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Training Framework for Deep Neural Network
Paper and Code
Mar 25, 2021
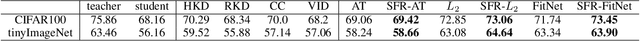
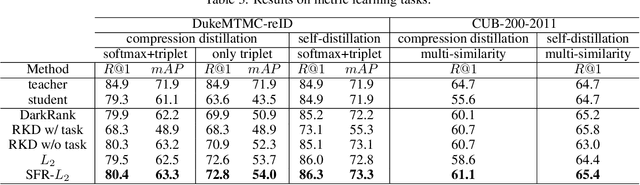
Knowledge distillation is the process of transferring the knowledge from a large model to a small model. In this process, the small model learns the generalization ability of the large model and retains the performance close to that of the large model. Knowledge distillation provides a training means to migrate the knowledge of models, facilitating model deployment and speeding up inference. However, previous distillation methods require pre-trained teacher models, which still bring computational and storage overheads. In this paper, a novel general training framework called Self Distillation (SD) is proposed. We demonstrate the effectiveness of our method by enumerating its performance improvements in diverse tasks and benchmark datasets.
* Withdraw this paper for internal review. Because we were not familiar
with the use of arXiv, our initial manuscript was uploaded by mistake and we
found many inappropriate and unmodified parts of it. I am sorry to say that
this work still needs to be further completed and we do not intend to use it
for publication
View paper on