Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model Explanation System: Latest Updates and Extensions
Paper and Code
Jun 30, 2016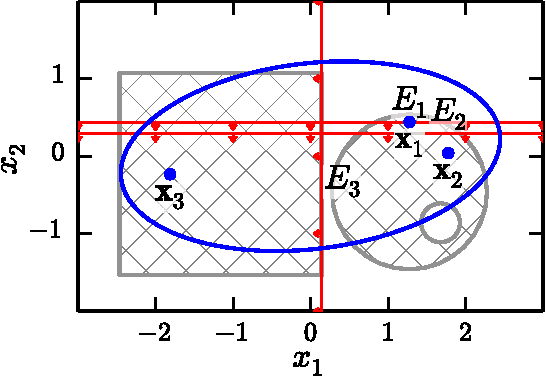


We propose a general model explanation system (MES) for "explaining" the output of black box classifiers. This paper describes extensions to Turner (2015), which is referred to frequently in the text. We use the motivating example of a classifier trained to detect fraud in a credit card transaction history. The key aspect is that we provide explanations applicable to a single prediction, rather than provide an interpretable set of parameters. We focus on explaining positive predictions (alerts). However, the presented methodology is symmetrically applicable to negative predictions.
* Presented at 2016 ICML Workshop on Human Interpretability in Machine
Learning (WHI 2016), New York, NY
View paper on