 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory Transformer Network for Incremental Learning
Paper and Code
Oct 10, 2022


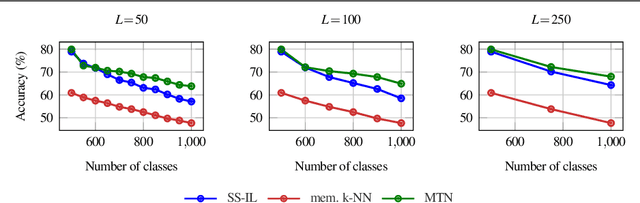
We study class-incremental learning, a training setup in which new classes of data are observed over time for the model to learn from. Despite the straightforward problem formulation, the naive application of classification models to class-incremental learning results in the "catastrophic forgetting" of previously seen classes. One of the most successful existing methods has been the use of a memory of exemplars, which overcomes the issue of catastrophic forgetting by saving a subset of past data into a memory bank and utilizing it to prevent forgetting when training future tasks. In our paper, we propose to enhance the utilization of this memory bank: we not only use it as a source of additional training data like existing works but also integrate it in the prediction process explicitly.Our method, the Memory Transformer Network (MTN), learns how to combine and aggregate the information from the nearest neighbors in the memory with a transformer to make more accurate predictions. We conduct extensive experiments and ablations to evaluate our approach. We show that MTN achieves state-of-the-art performance on the challenging ImageNet-1k and Google-Landmarks-1k incremental learning benchmarks.