 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Max-Sum algorithm for training discrete neural networks
Paper and Code
Aug 13, 2015

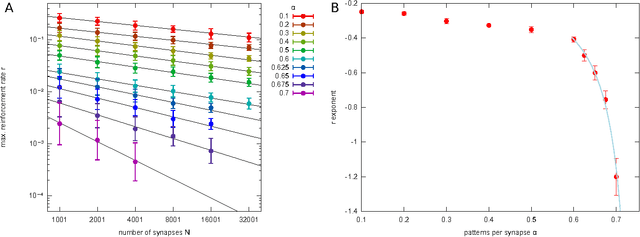
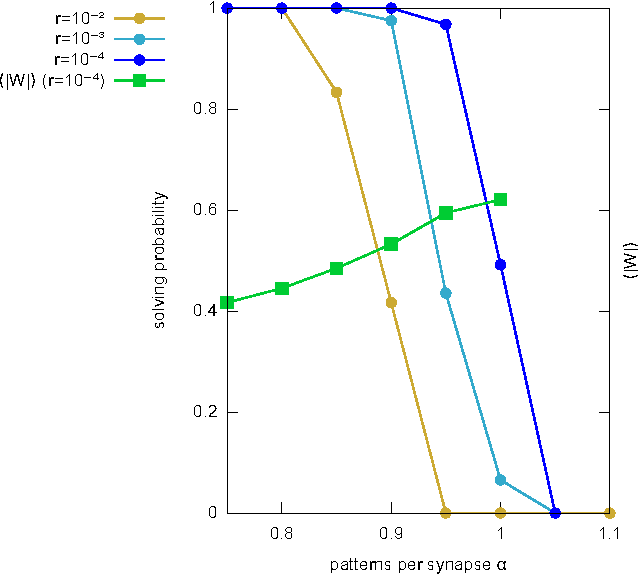
We present an efficient learning algorithm for the problem of training neural networks with discrete synapses, a well-known hard (NP-complete) discrete optimization problem. The algorithm is a variant of the so-called Max-Sum (MS) algorithm. In particular, we show how, for bounded integer weights with $q$ distinct states and independent concave a priori distribution (e.g. $l_{1}$ regularization), the algorithm's time complexity can be made to scale as $O\left(N\log N\right)$ per node update, thus putting it on par with alternative schemes, such as Belief Propagation (BP), without resorting to approximations. Two special cases are of particular interest: binary synapses $W\in\{-1,1\}$ and ternary synapses $W\in\{-1,0,1\}$ with $l_{0}$ regularization. The algorithm we present performs as well as BP on binary perceptron learning problems, and may be better suited to address the problem on fully-connected two-layer networks, since inherent symmetries in two layer networks are naturally broken using the MS approach.