 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mathematical Programming approach to Binary Supervised Classification with Label Noise
Paper and Code
Apr 21, 2020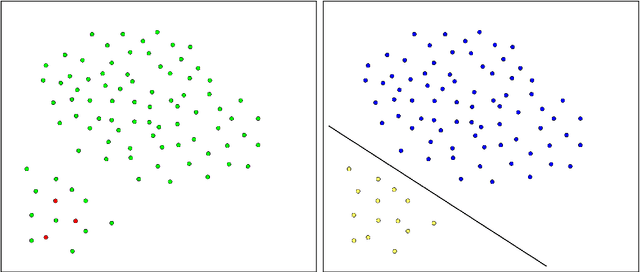
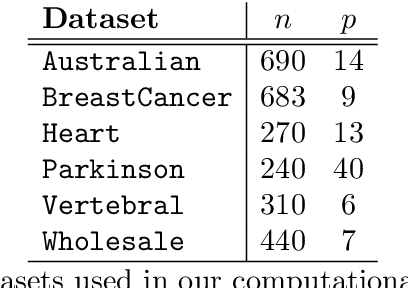
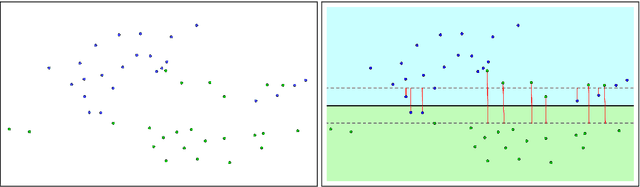
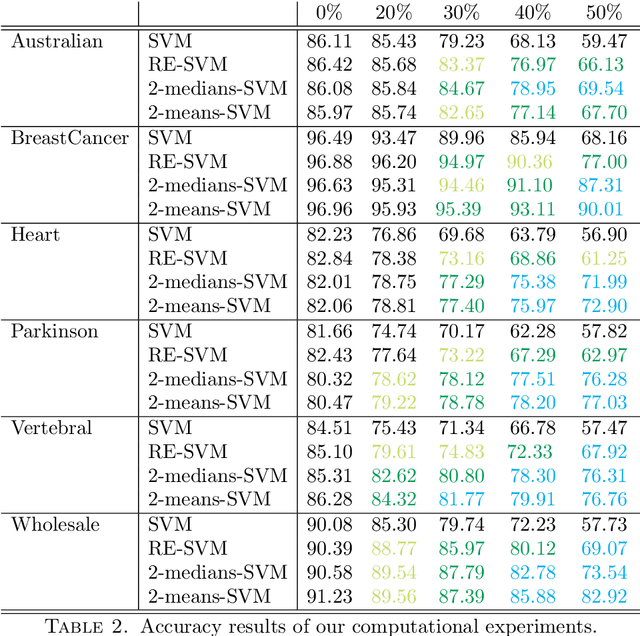
In this paper we propose novel methodologies to construct Support Vector Machine -based classifiers that takes into account that label noises occur in the training sample. We propose different alternatives based on solving Mixed Integer Linear and Non Linear models by incorporating decisions on relabeling some of the observations in the training dataset. The first method incorporates relabeling directly in the SVM model while a second family of methods combines clustering with classification at the same time, giving rise to a model that applies simultaneously similarity measures and SVM. Extensive computational experiments are reported based on a battery of standard datasets taken from UCI Machine Learning repository, showing the effectiveness of the proposed approaches.