 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA layer-wise analysis of Mandarin and English suprasegmentals in SSL speech models
Paper and Code
Aug 24, 2024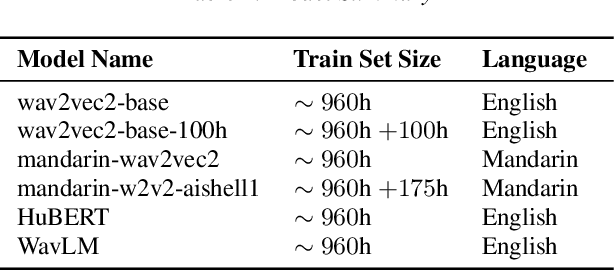



This study asks how self-supervised speech models represent suprasegmental categories like Mandarin lexical tone, English lexical stress, and English phrasal accents. Through a series of probing tasks, we make layer-wise comparisons of English and Mandarin 12 layer monolingual models. Our findings suggest that 1) English and Mandarin wav2vec 2.0 models learn contextual representations of abstract suprasegmental categories which are strongest in the middle third of the network. 2) Models are better at representing features that exist in the language of their training data, and this difference is driven by enriched context in transformer blocks, not local acoustic representation. 3) Fine-tuned wav2vec 2.0 improves performance in later layers compared to pre-trained models mainly for lexically contrastive features like tone and stress, 4) HuBERT and WavLM learn similar representations to wav2vec 2.0, differing mainly in later layer performance. Our results extend previous understanding of how models represent suprasegmentals and offer new insights into the language-specificity and contextual nature of these representations.