 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Corpus of Gulf Arabic
Paper and Code
Sep 09, 2016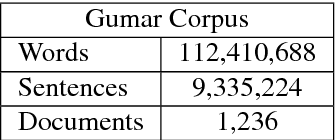
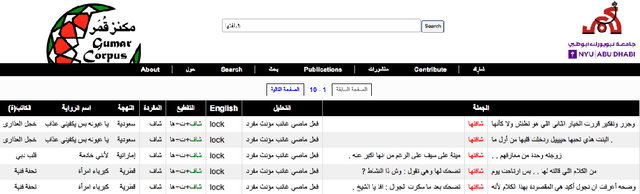
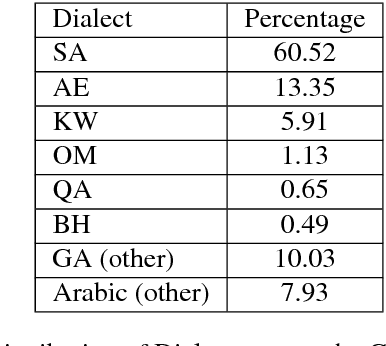
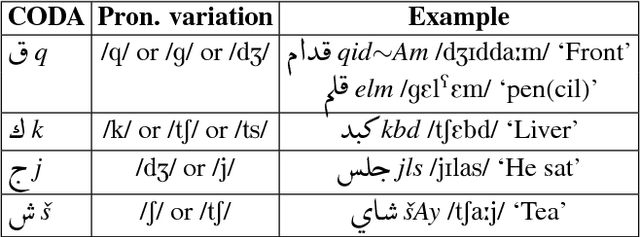
Most Arabic natural language processing tools and resources are developed to serve Modern Standard Arabic (MSA), which is the official written language in the Arab World. Some Dialectal Arabic varieties, notably Egyptian Arabic, have received some attention lately and have a growing collection of resources that include annotated corpora and morphological analyzers and taggers. Gulf Arabic, however, lags behind in that respect. In this paper, we present the Gumar Corpus, a large-scale corpus of Gulf Arabic consisting of 110 million words from 1,200 forum novels. We annotate the corpus for sub-dialect information at the document level. We also present results of a preliminary study in the morphological annotation of Gulf Arabic which includes developing guidelines for a conventional orthography. The text of the corpus is publicly browsable through a web interface we developed for it.