Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA highly likely clusterable data model with no clusters
Paper and Code
Sep 14, 2019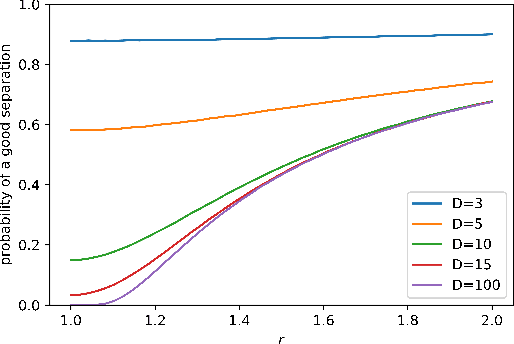

We propose a model for a dataset in ${\mathbb R}^D$ that does not contain any clusters but yet is such that a projection of the points on a random one-dimensional subspace is likely to yield a clustering of the points. This model is compatible with some recent empirical observations.
View paper on