 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Model for Spoken Language Recognition
Paper and Code
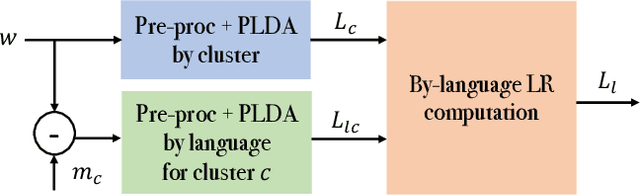
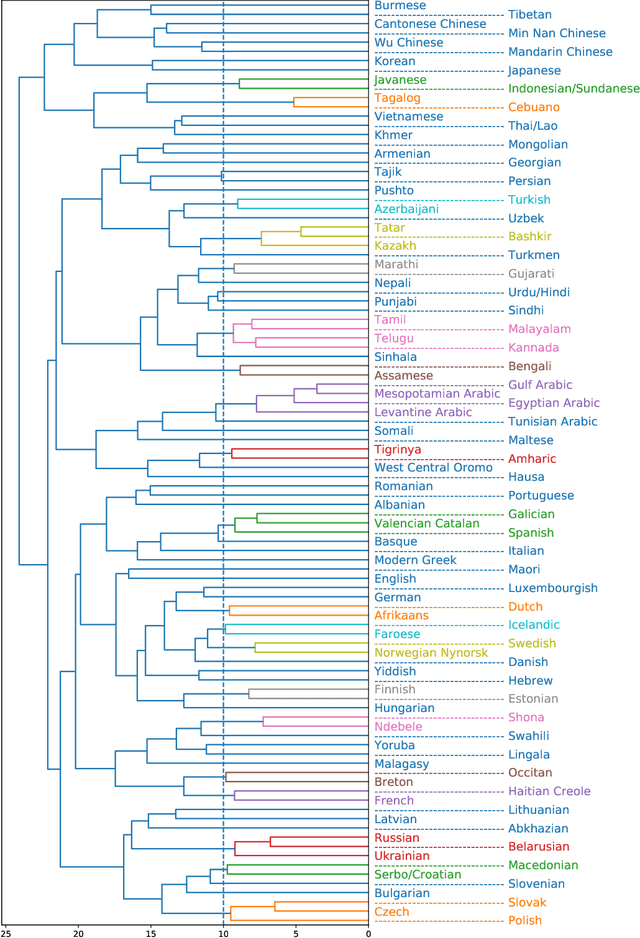
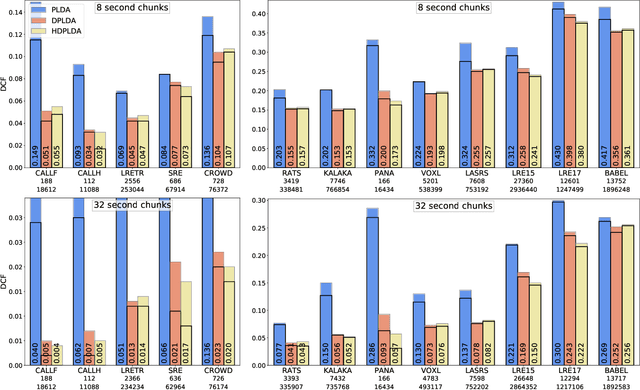
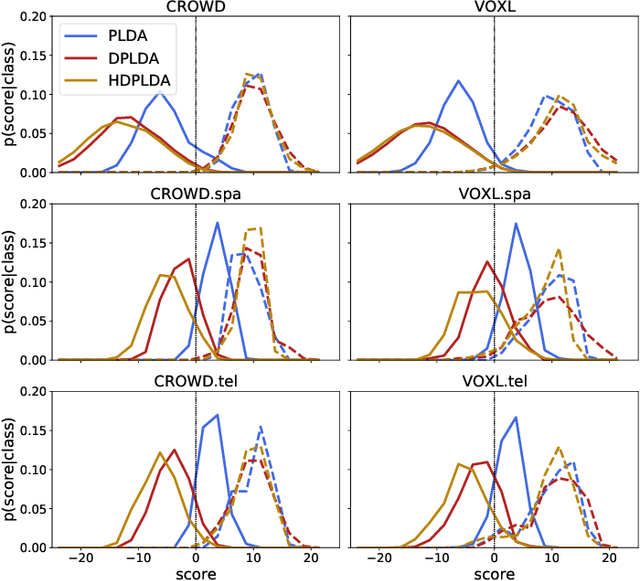
Spoken language recognition (SLR) refers to the automatic process used to determine the language present in a speech sample. SLR is an important task in its own right, for example, as a tool to analyze or categorize large amounts of multi-lingual data. Further, it is also an essential tool for selecting downstream applications in a work flow, for example, to chose appropriate speech recognition or machine translation models. SLR systems are usually composed of two stages, one where an embedding representing the audio sample is extracted and a second one which computes the final scores for each language. In this work, we approach the SLR task as a detection problem and implement the second stage as a probabilistic linear discriminant analysis (PLDA) model. We show that discriminative training of the PLDA parameters gives large gains with respect to the usual generative training. Further, we propose a novel hierarchical approach were two PLDA models are trained, one to generate scores for clusters of highly related languages and a second one to generate scores conditional to each cluster. The final language detection scores are computed as a combination of these two sets of scores. The complete model is trained discriminatively to optimize a cross-entropy objective. We show that this hierarchical approach consistently outperforms the non-hierarchical one for detection of highly related languages, in many cases by large margins. We train our systems on a collection of datasets including 100 languages and test them both on matched and mismatched conditions, showing that the gains are robust to condition mismatch.