 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generic and efficient convolutional neural network accelerator using HLS for a system on chip design
Paper and Code
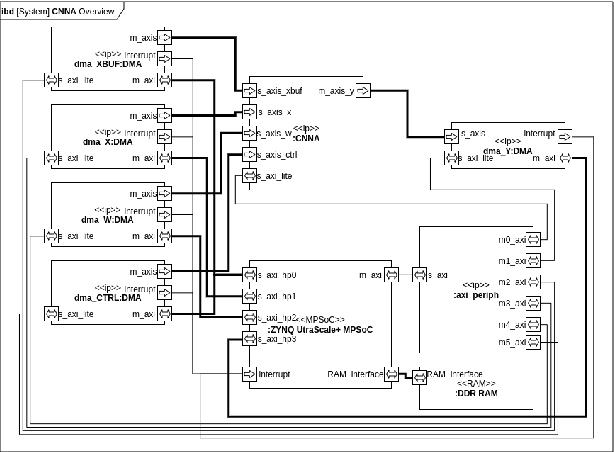
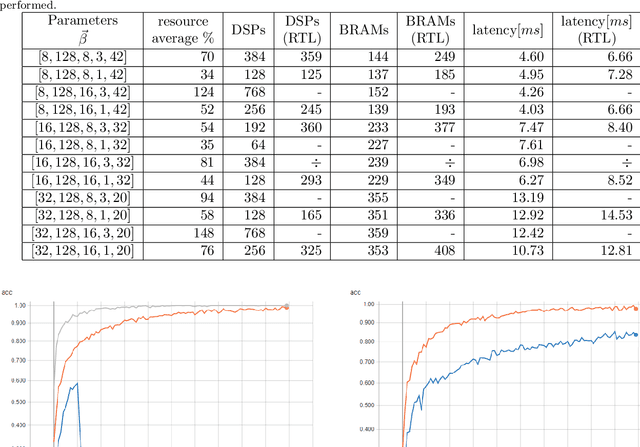
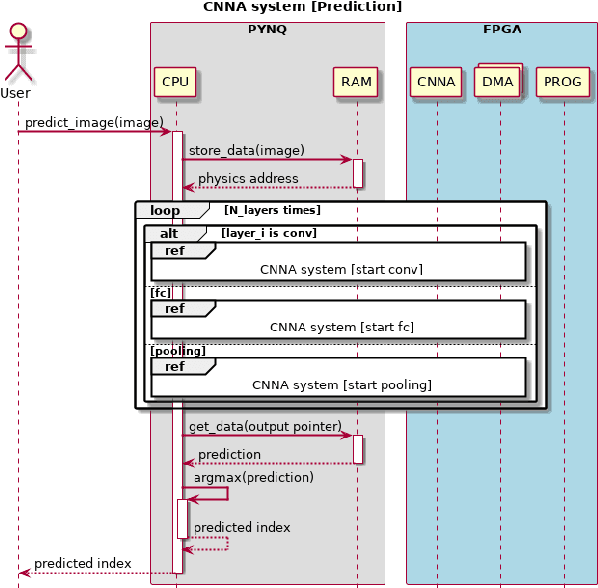
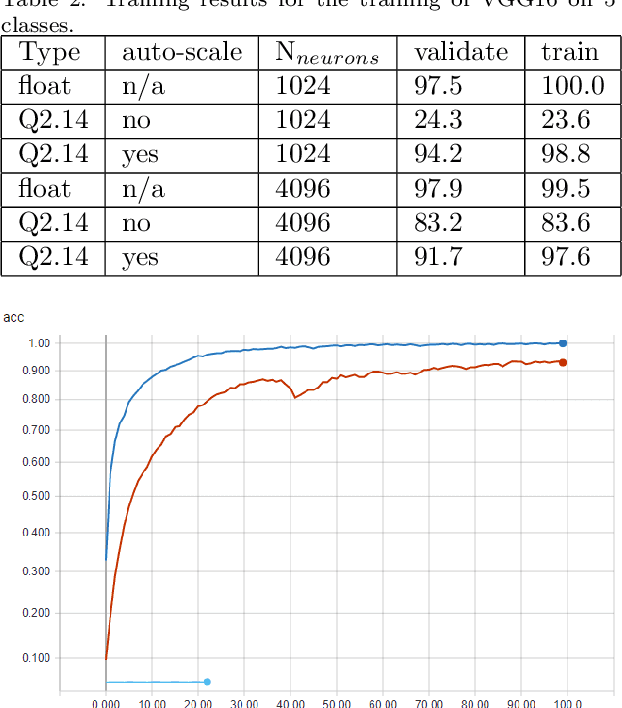
This paper presents a generic convolutional neural network accelerator (CNNA) for a system on chip design (SoC). The goal was to accelerate inference of different deep learning networks on an embedded SoC platform. The presented CNNA has a scalable architecture which uses high level synthesis (HLS) and SystemC for the hardware accelerator. It is able to accelerate any CNN exported from Python and supports a combination of convolutional, max-pooling, and fully connected layers. A training method using fixed-point quantized weights is proposed and presented in the paper. The CNNA is template-based, enabling it to scale for different targets of the Xilinx ZYNQ platform. This approach enables design space exploration, which makes it possible to explore several configurations of the CNNA during C- and RTL-simulation, fitting it to the desired platform and model. The convolutional neural network VGG16 was used to test the solution on a Xilinx Ultra96 board. The result gave a high accuracy in training with an auto-scaled fixed-point Q2.14 format compared to a similar floating-point model. It was able to perform inference in 2.0 seconds, while having an average power consumption of 2.63 W, which corresponds to a power efficiency of 6.0 GOPS/W for the CNN accelerator.