 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Zero-Shot Quantization of Deep Convolutional Neural Networks via Learned Weights Statistics
Paper and Code
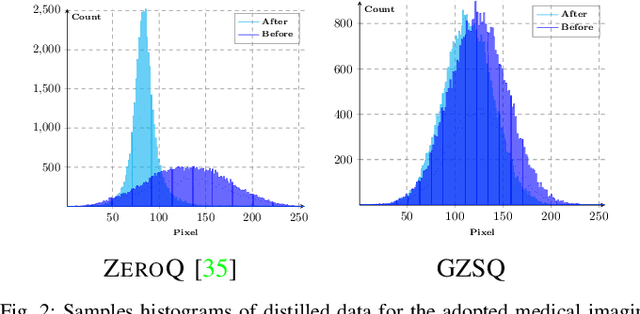
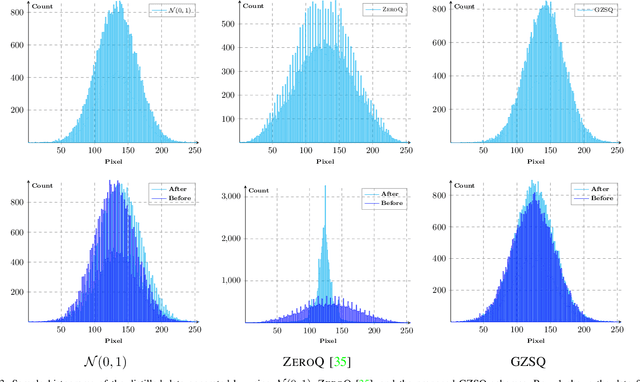
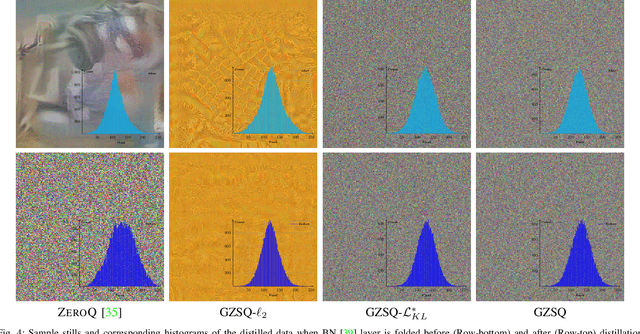
Quantizing the floating-point weights and activations of deep convolutional neural networks to fixed-point representation yields reduced memory footprints and inference time. Recently, efforts have been afoot towards zero-shot quantization that does not require original unlabelled training samples of a given task. These best-published works heavily rely on the learned batch normalization (BN) parameters to infer the range of the activations for quantization. In particular, these methods are built upon either empirical estimation framework or the data distillation approach, for computing the range of the activations. However, the performance of such schemes severely degrades when presented with a network that does not accommodate BN layers. In this line of thought, we propose a generalized zero-shot quantization (GZSQ) framework that neither requires original data nor relies on BN layer statistics. We have utilized the data distillation approach and leveraged only the pre-trained weights of the model to estimate enriched data for range calibration of the activations. To the best of our knowledge, this is the first work that utilizes the distribution of the pretrained weights to assist the process of zero-shot quantization. The proposed scheme has significantly outperformed the existing zero-shot works, e.g., an improvement of ~ 33% in classification accuracy for MobileNetV2 and several other models that are w & w/o BN layers, for a variety of tasks. We have also demonstrated the efficacy of the proposed work across multiple open-source quantization frameworks. Importantly, our work is the first attempt towards the post-training zero-shot quantization of futuristic unnormalized deep neural networks.