Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fusion method for multi-valued data
Paper and Code
Jan 25, 2021
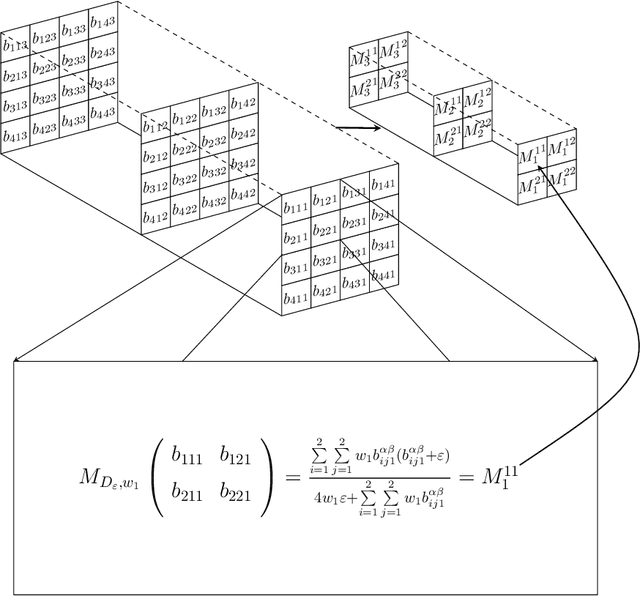


In this paper we propose an extension of the notion of deviation-based aggregation function tailored to aggregate multidimensional data. Our objective is both to improve the results obtained by other methods that try to select the best aggregation function for a particular set of data, such as penalty functions, and to reduce the temporal complexity required by such approaches. We discuss how this notion can be defined and present three illustrative examples of the applicability of our new proposal in areas where temporal constraints can be strict, such as image processing, deep learning and decision making, obtaining favourable results in the process.
* Information Fusion, Volume 71, 2021, Pages 1-10
View paper on