 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Functional Perspective on Learning Symmetric Functions with Neural Networks
Paper and Code
Aug 16, 2020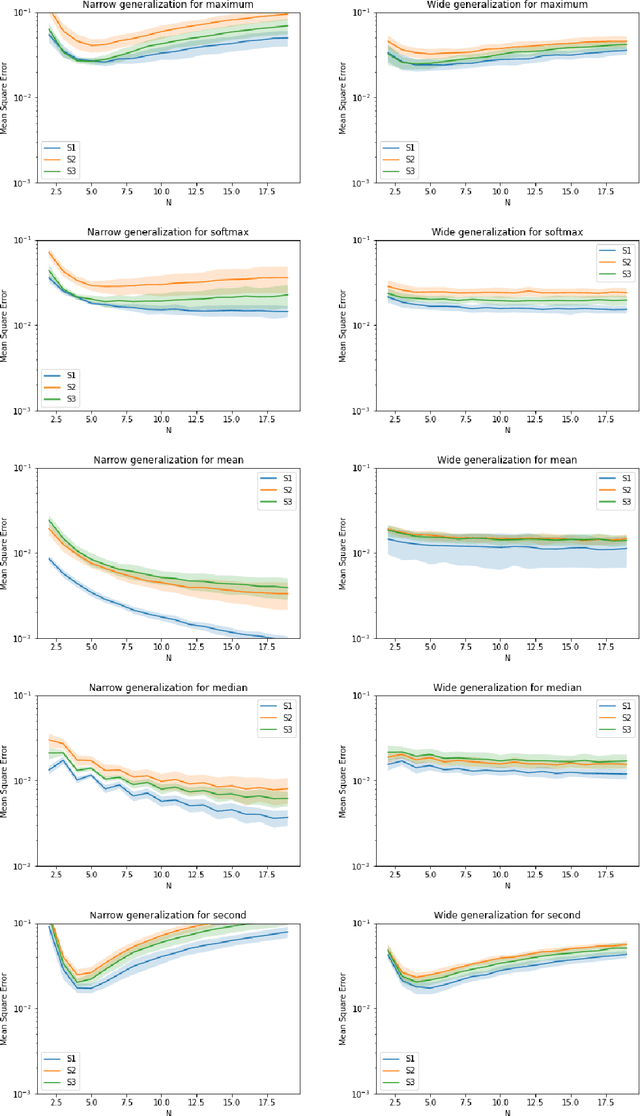
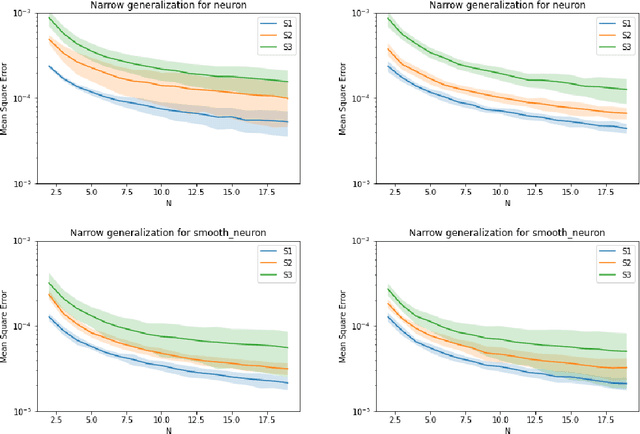
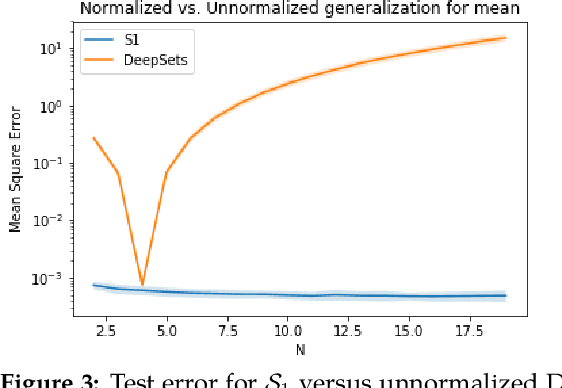
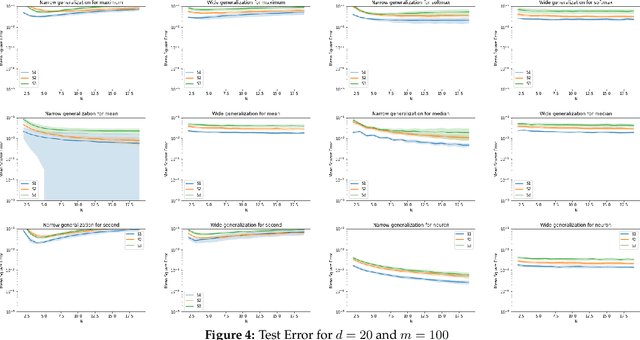
Symmetric functions, which take as input an unordered, fixed-size set, are known to be universally representable by neural networks that enforce permutation invariance. However, these architectures only give guarantees for fixed input sizes, yet in many practical scenarios, such as particle physics, a relevant notion of generalization should include varying the input size. In this paper, we embed symmetric functions (of any size) as functions over probability measures, and study the ability of neural networks defined over this space of measures to represent and learn in that space. By focusing on shallow architectures, we establish approximation and generalization bounds under different choices of regularization (such as RKHS and variation norms), that capture a hierarchy of functional spaces with increasing amount of non-linear learning. The resulting models can be learnt efficiently and enjoy generalization guarantees that extend across input sizes, as we verify empirically.