 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Convolutional Neural Network Approach to End-to-End Speech Enhancement
Paper and Code
Jul 20, 2018
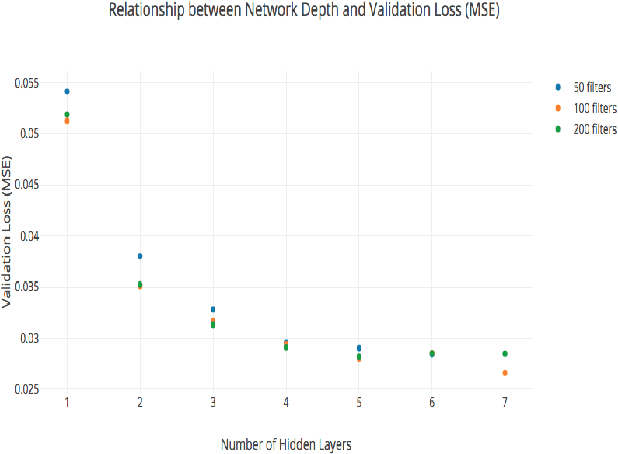
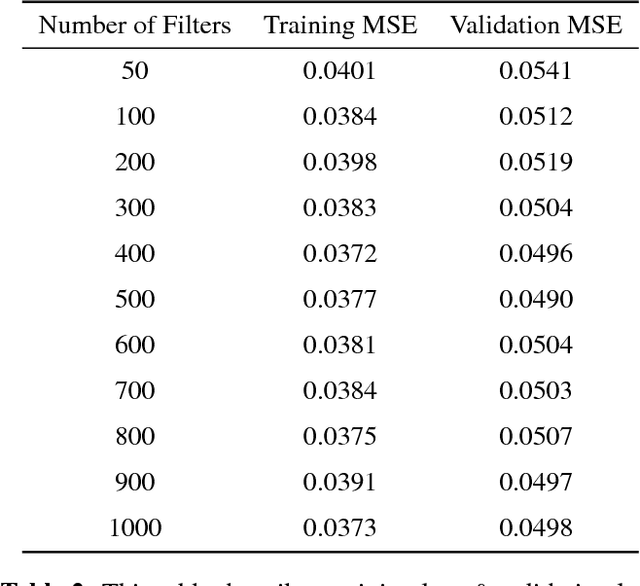
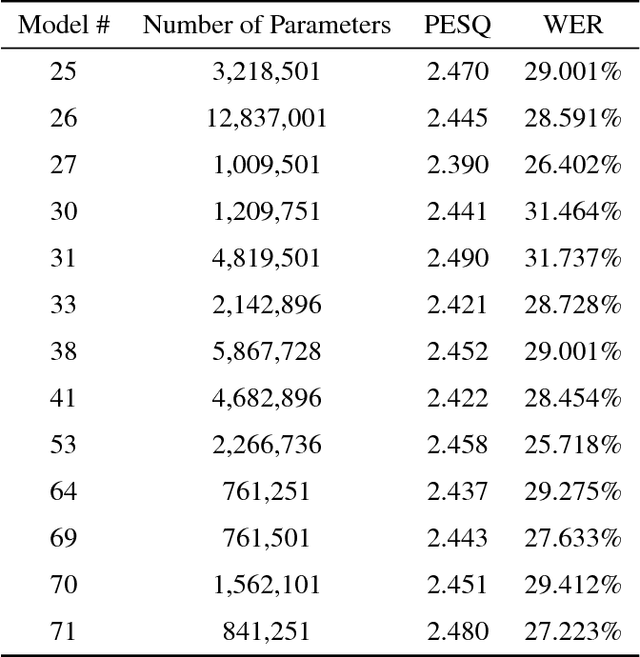
This paper will describe a novel approach to the cocktail party problem that relies on a fully convolutional neural network (FCN) architecture. The FCN takes noisy audio data as input and performs nonlinear, filtering operations to produce clean audio data of the target speech at the output. Our method learns a model for one specific speaker, and is then able to extract that speakers voice from babble background noise. Results from experimentation indicate the ability to generalize to new speakers and robustness to new noise environments of varying signal-to-noise ratios. A potential application of this method would be for use in hearing aids. A pre-trained model could be quickly fine tuned for an individuals family members and close friends, and deployed onto a hearing aid to assist listeners in noisy environments.