 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework and Benchmarking Study for Counterfactual Generating Methods on Tabular Data
Paper and Code
Jul 09, 2021

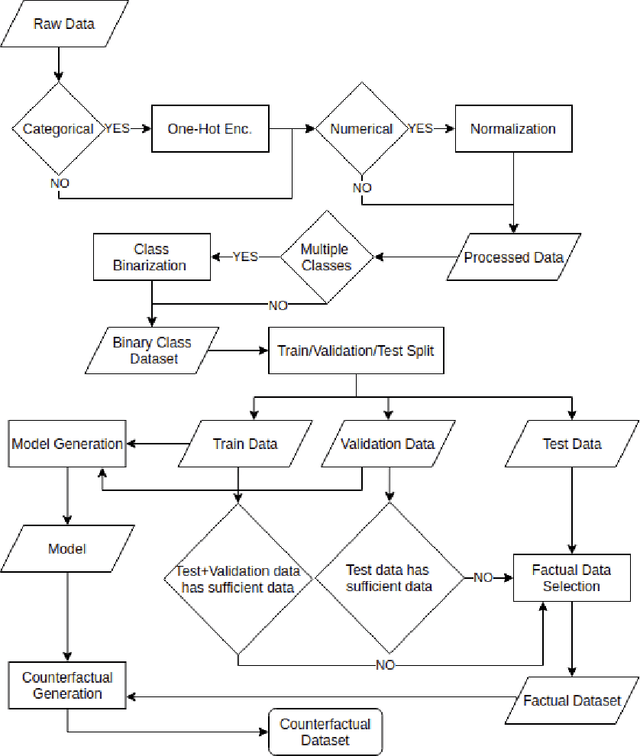

Counterfactual explanations are viewed as an effective way to explain machine learning predictions. This interest is reflected by a relatively young literature with already dozens of algorithms aiming to generate such explanations. These algorithms are focused on finding how features can be modified to change the output classification. However, this rather general objective can be achieved in different ways, which brings about the need for a methodology to test and benchmark these algorithms. The contributions of this work are manifold: First, a large benchmarking study of 10 algorithmic approaches on 22 tabular datasets is performed, using 9 relevant evaluation metrics. Second, the introduction of a novel, first of its kind, framework to test counterfactual generation algorithms. Third, a set of objective metrics to evaluate and compare counterfactual results. And finally, insight from the benchmarking results that indicate which approaches obtain the best performance on what type of dataset. This benchmarking study and framework can help practitioners in determining which technique and building blocks most suit their context, and can help researchers in the design and evaluation of current and future counterfactual generation algorithms. Our findings show that, overall, there's no single best algorithm to generate counterfactual explanations as the performance highly depends on properties related to the dataset, model, score and factual point specificities.