 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fast algorithm with minimax optimal guarantees for topic models with an unknown number of topics
Paper and Code
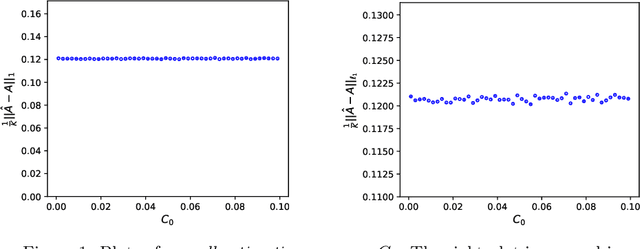

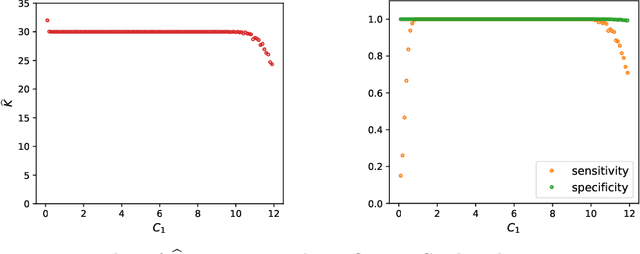
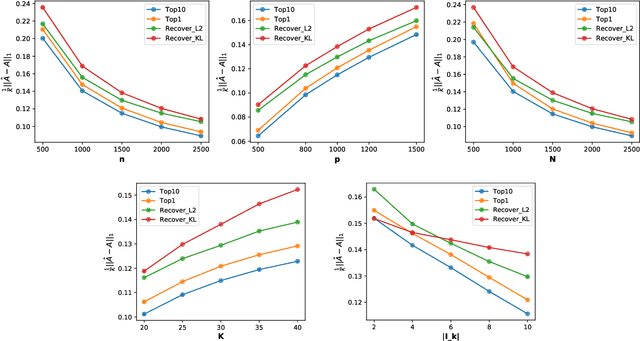
We propose a new method of estimation in topic models, that is not a variation on the existing simplex finding algorithms, and that estimates the number of topics K from the observed data. We derive new finite sample minimax lower bounds for the estimation of A, as well as new upper bounds for our proposed estimator. We describe the scenarios where our estimator is minimax adaptive. Our finite sample analysis is valid for any number of documents (n), individual document length (N_i), dictionary size (p) and number of topics (K), and both p and K are allowed to increase with n, a situation not handled well by previous analyses. We complement our theoretical results with a detailed simulation study. We illustrate that the new algorithm is faster and more accurate than the current ones, although we start out with a computational and theoretical disadvantage of not knowing the correct number of topics K, while we provide the competing methods with the correct value in our simulations.