Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Algorithm for Training Nonlinear Kernel Machines
Paper and Code
May 18, 2014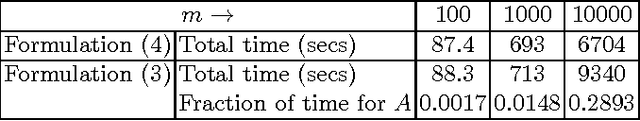
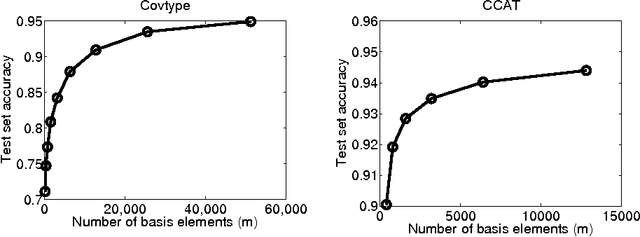
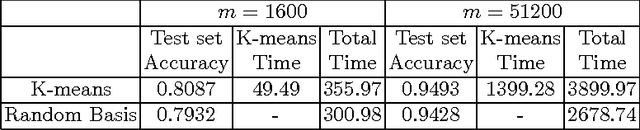

This paper concerns the distributed training of nonlinear kernel machines on Map-Reduce. We show that a re-formulation of Nystr\"om approximation based solution which is solved using gradient based techniques is well suited for this, especially when it is necessary to work with a large number of basis points. The main advantages of this approach are: avoidance of computing the pseudo-inverse of the kernel sub-matrix corresponding to the basis points; simplicity and efficiency of the distributed part of the computations; and, friendliness to stage-wise addition of basis points. We implement the method using an AllReduce tree on Hadoop and demonstrate its value on a few large benchmark datasets.
View paper on