 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA discriminative condition-aware backend for speaker verification
Paper and Code
Nov 26, 2019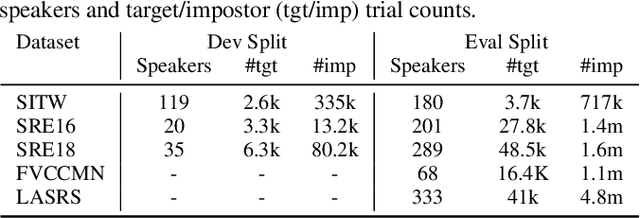
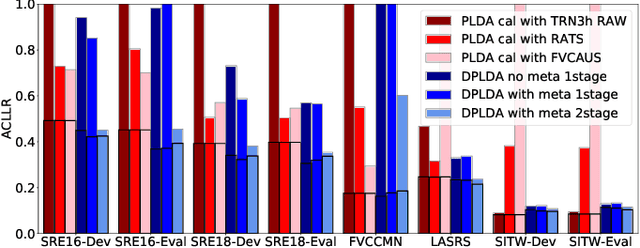
We present a scoring approach for speaker verification that mimics the standard PLDA-based backend process used in most current speaker verification systems. However, unlike the standard backends, all parameters of the model are jointly trained to optimize the binary cross-entropy for the speaker verification task. We further integrate the calibration stage inside the model, making the parameters of this stage depend on metadata vectors that represent the conditions of the signals. We show that the proposed backend has excellent out-of-the-box calibration performance on most of our test sets, making it an ideal approach for cases in which the test conditions are not known and development data is not available for training a domain-specific calibration model.