 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentially Private Text Perturbation Method Using a Regularized Mahalanobis Metric
Paper and Code
Oct 22, 2020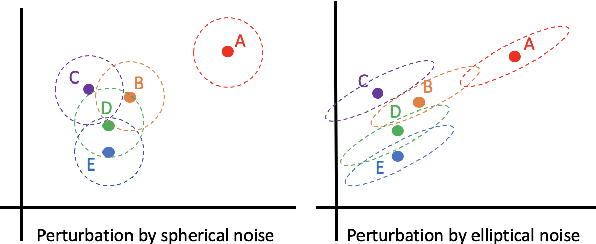


Balancing the privacy-utility tradeoff is a crucial requirement of many practical machine learning systems that deal with sensitive customer data. A popular approach for privacy-preserving text analysis is noise injection, in which text data is first mapped into a continuous embedding space, perturbed by sampling a spherical noise from an appropriate distribution, and then projected back to the discrete vocabulary space. While this allows the perturbation to admit the required metric differential privacy, often the utility of downstream tasks modeled on this perturbed data is low because the spherical noise does not account for the variability in the density around different words in the embedding space. In particular, words in a sparse region are likely unchanged even when the noise scale is large. %Using the global sensitivity of the mechanism can potentially add too much noise to the words in the dense regions of the embedding space, causing a high utility loss, whereas using local sensitivity can leak information through the scale of the noise added. In this paper, we propose a text perturbation mechanism based on a carefully designed regularized variant of the Mahalanobis metric to overcome this problem. For any given noise scale, this metric adds an elliptical noise to account for the covariance structure in the embedding space. This heterogeneity in the noise scale along different directions helps ensure that the words in the sparse region have sufficient likelihood of replacement without sacrificing the overall utility. We provide a text-perturbation algorithm based on this metric and formally prove its privacy guarantees. Additionally, we empirically show that our mechanism improves the privacy statistics to achieve the same level of utility as compared to the state-of-the-art Laplace mechanism.