 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Detailed Study of Interpretability of Deep Neural Network based Top Taggers
Paper and Code
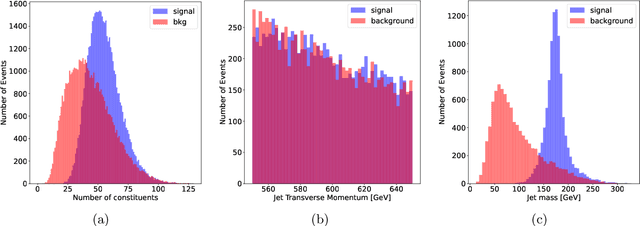
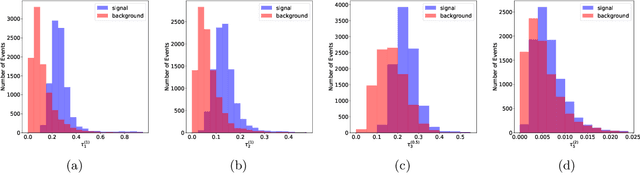
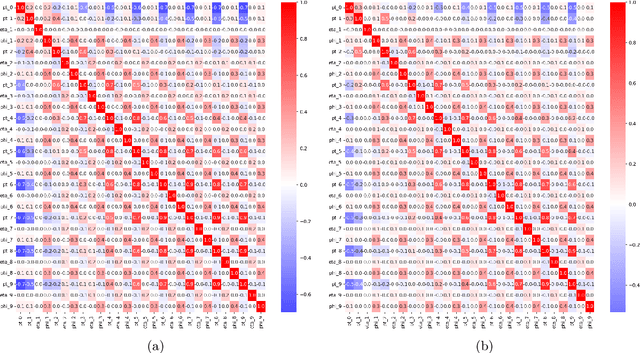
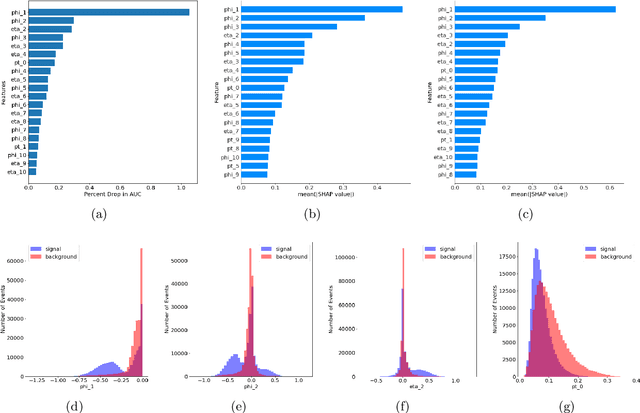
Recent developments in the methods of explainable AI (xAI) methods allow us to explore the inner workings of deep neural networks (DNNs), revealing crucial information about input-output relationships and realizing how data connects with machine learning models. In this paper we explore interpretability of DNN models designed for identifying jets coming from top quark decay in the high energy proton-proton collisions at the Large Hadron Collider (LHC). We review a subset of existing such top tagger models and explore different quantitative methods to identify which features play the most important roles in identifying the top jets. We also investigate how and why feature importance varies across different xAI metrics, how feature correlations impact their explainability, and how latent space representations encode information as well as correlate with physically meaningful quantities. Our studies uncover some major pitfalls of existing xAI methods and illustrate how they can be overcome to obtain consistent and meaningful interpretation of these models. We additionally illustrate the activity of hidden layers as Neural Activation Pattern (NAP) diagrams and demonstrate how they can be used to understand how DNNs relay information across the layers and how this understanding can help us to make such models significantly simpler by allowing effective model reoptimization and hyperparameter tuning. While the primary focus of this work remains a detailed study of interpretability of DNN-based top tagger models, it also features state-of-the art performance obtained from modified implementation of existing networks.