 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Neural Network for Short-Segment Speaker Recognition
Paper and Code
Jul 22, 2019
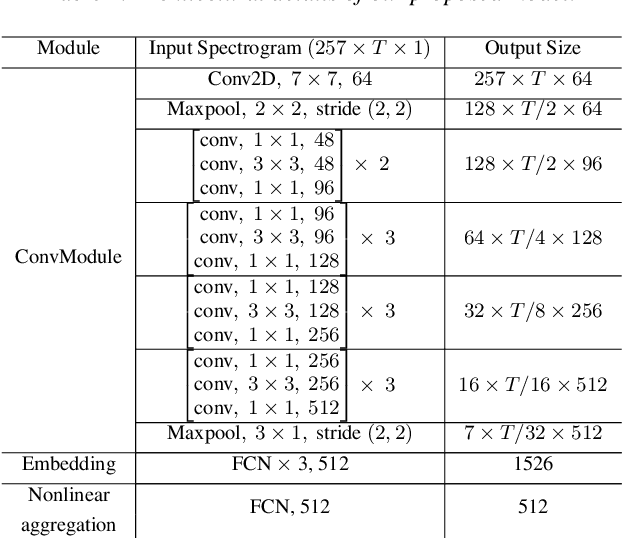


Todays interactive devices such as smart-phone assistants and smart speakers often deal with short-duration speech segments. As a result, speaker recognition systems integrated into such devices will be much better suited with models capable of performing the recognition task with short-duration utterances. In this paper, a new deep neural network, UtterIdNet, capable of performing speaker recognition with short speech segments is proposed. Our proposed model utilizes a novel architecture that makes it suitable for short-segment speaker recognition through an efficiently increased use of information in short speech segments. UtterIdNet has been trained and tested on the VoxCeleb datasets, the latest benchmarks in speaker recognition. Evaluations for different segment durations show consistent and stable performance for short segments, with significant improvement over the previous models for segments of 2 seconds, 1 second, and especially sub-second durations (250 ms and 500 ms).