Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critique of a Critique of Word Similarity Datasets: Sanity Check or Unnecessary Confusion?
Paper and Code
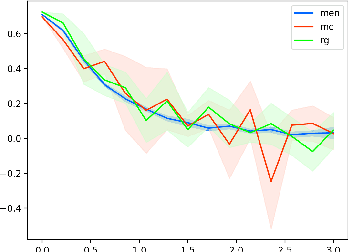
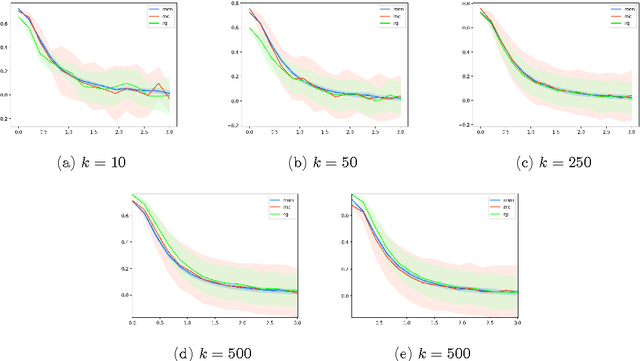
Critical evaluation of word similarity datasets is very important for computational lexical semantics. This short report concerns the sanity check proposed in Batchkarov et al. (2016) to evaluate several popular datasets such as MC, RG and MEN -- the first two reportedly failed. I argue that this test is unstable, offers no added insight, and needs major revision in order to fulfill its purported goal.
View paper on