 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA connection between the pattern classification problem and the General Linear Model for statistical inference
Paper and Code
Dec 16, 2020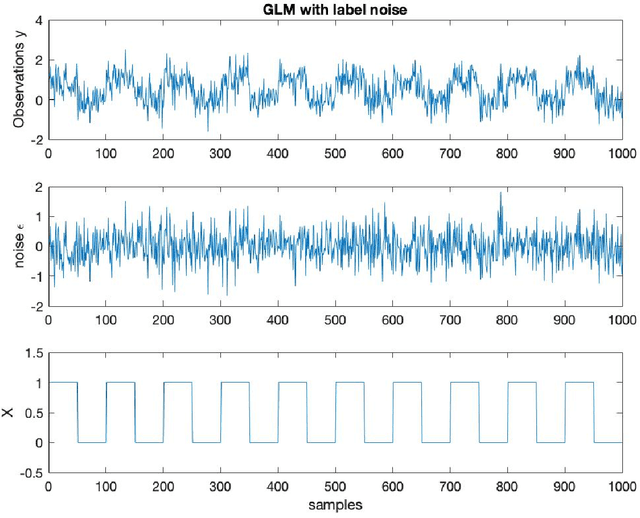

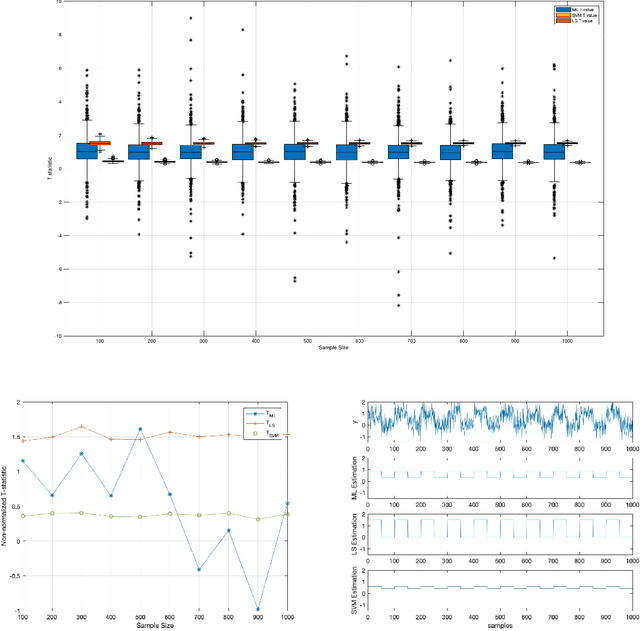
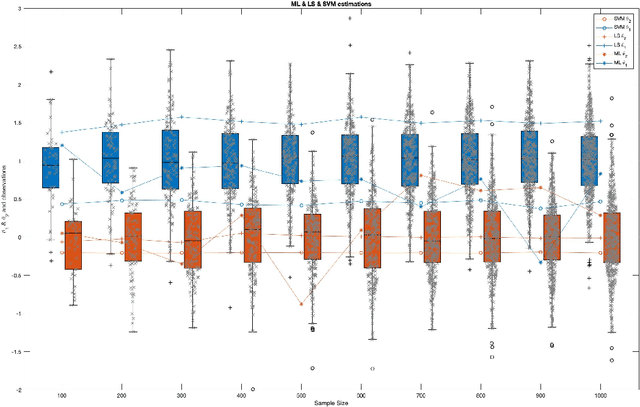
A connection between the General Linear Model (GLM) in combination with classical statistical inference and the machine learning (MLE)-based inference is described in this paper. Firstly, the estimation of the GLM parameters is expressed as a Linear Regression Model (LRM) of an indicator matrix, that is, in terms of the inverse problem of regressing the observations. In other words, both approaches, i.e. GLM and LRM, apply to different domains, the observation and the label domains, and are linked by a normalization value at the least-squares solution. Subsequently, from this relationship we derive a statistical test based on a more refined predictive algorithm, i.e. the (non)linear Support Vector Machine (SVM) that maximizes the class margin of separation, within a permutation analysis. The MLE-based inference employs a residual score and includes the upper bound to compute a better estimation of the actual (real) error. Experimental results demonstrate how the parameter estimations derived from each model resulted in different classification performances in the equivalent inverse problem. Moreover, using real data the aforementioned predictive algorithms within permutation tests, including such model-free estimators, are able to provide a good trade-off between type I error and statistical power.