 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Brief Study on the Effects of Training Generative Dialogue Models with a Semantic loss
Paper and Code
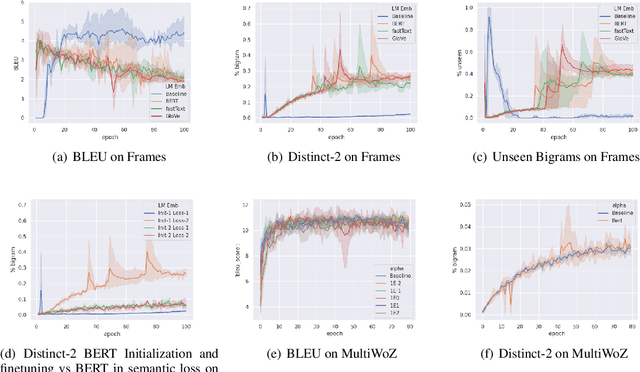



Neural models trained for next utterance generation in dialogue task learn to mimic the n-gram sequences in the training set with training objectives like negative log-likelihood (NLL) or cross-entropy. Such commonly used training objectives do not foster generating alternate responses to a context. But, the effects of minimizing an alternate training objective that fosters a model to generate alternate response and score it on semantic similarity has not been well studied. We hypothesize that a language generation model can improve on its diversity by learning to generate alternate text during training and minimizing a semantic loss as an auxiliary objective. We explore this idea on two different sized data sets on the task of next utterance generation in goal oriented dialogues. We make two observations (1) minimizing a semantic objective improved diversity in responses in the smaller data set (Frames) but only as-good-as minimizing the NLL in the larger data set (MultiWoZ) (2) large language model embeddings can be more useful as a semantic loss objective than as initialization for token embeddings.