 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayes-Optimal View on Adversarial Examples
Paper and Code
Feb 20, 2020
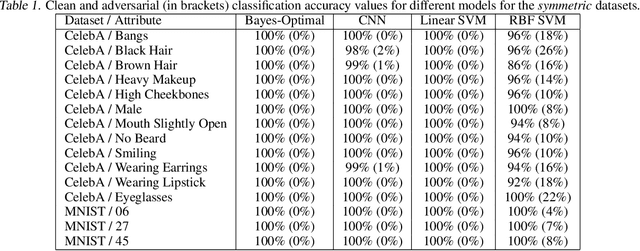

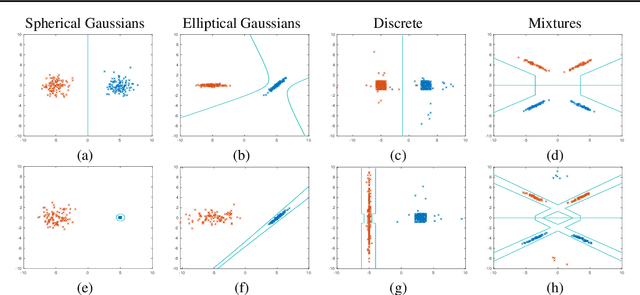
The ability to fool modern CNN classifiers with tiny perturbations of the input has lead to the development of a large number of candidate defenses and often conflicting explanations. In this paper, we argue for examining adversarial examples from the perspective of Bayes-Optimal classification. We construct realistic image datasets for which the Bayes-Optimal classifier can be efficiently computed and derive analytic conditions on the distributions so that the optimal classifier is either robust or vulnerable. By training different classifiers on these datasets (for which the "gold standard" optimal classifiers are known), we can disentangle the possible sources of vulnerability and avoid the accuracy-robustness tradeoff that may occur in commonly used datasets. Our results show that even when the optimal classifier is robust, standard CNN training consistently learns a vulnerable classifier. At the same time, for exactly the same training data, RBF SVMs consistently learn a robust classifier. The same trend is observed in experiments with real images.