Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DFeat-Net: Weakly Supervised Local 3D Features for Point Cloud Registration
Paper and Code


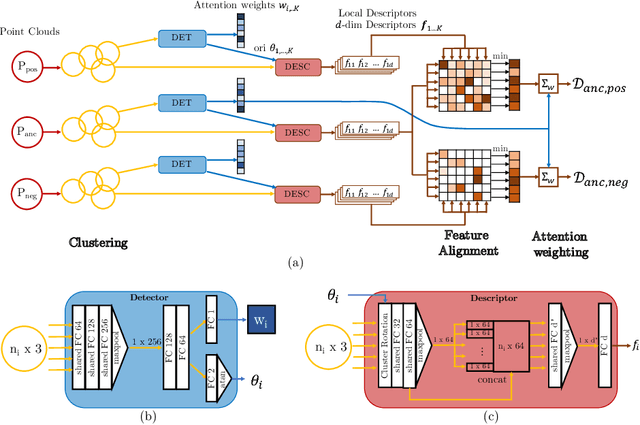
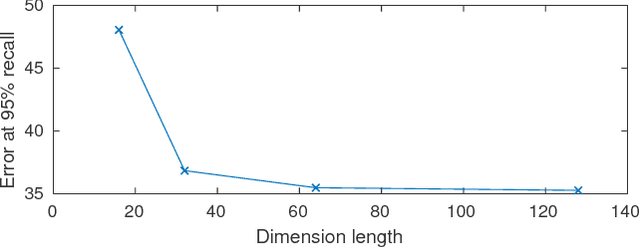
In this paper, we propose the 3DFeat-Net which learns both 3D feature detector and descriptor for point cloud matching using weak supervision. Unlike many existing works, we do not require manual annotation of matching point clusters. Instead, we leverage on alignment and attention mechanisms to learn feature correspondences from GPS/INS tagged 3D point clouds without explicitly specifying them. We create training and benchmark outdoor Lidar datasets, and experiments show that 3DFeat-Net obtains state-of-the-art performance on these gravity-aligned datasets.
* 17 pages, 6 figures. Accepted in ECCV 2018
View paper on