Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Semantic Scene Completion from a Single Depth Image using Adversarial Training
Paper and Code
May 15, 2019
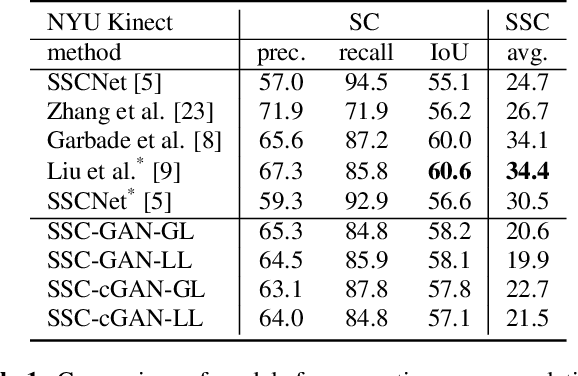
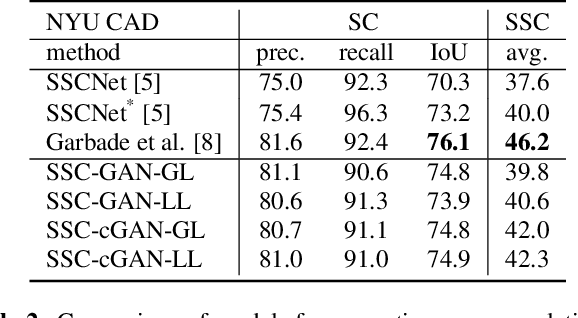

We address the task of 3D semantic scene completion, i.e. , given a single depth image, we predict the semantic labels and occupancy of voxels in a 3D grid representing the scene. In light of the recently introduced generative adversarial networks (GAN), our goal is to explore the potential of this model and the efficiency of various important design choices. Our results show that using conditional GANs outperforms the vanilla GAN setup. We evaluate these architecture designs on several datasets. Based on our experiments, we demonstrate that GANs are able to outperform the performance of a baseline 3D CNN in case of clean annotations, but they suffer from poorly aligned annotations.
View paper on