 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Convolution Guided Spectral-Spatial Transformer for Hyperspectral Image Classification
Paper and Code
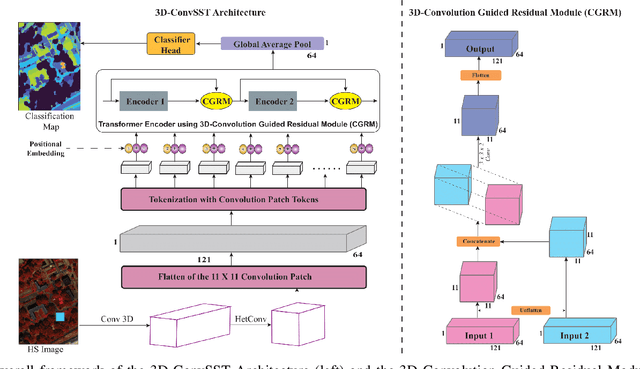
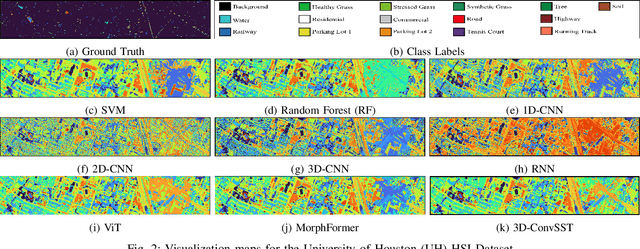
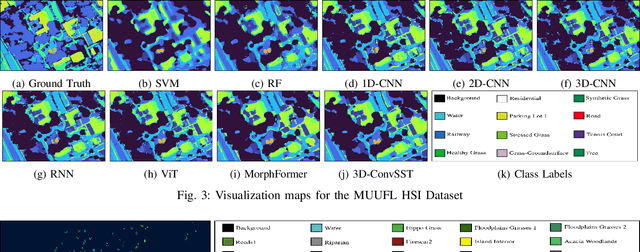
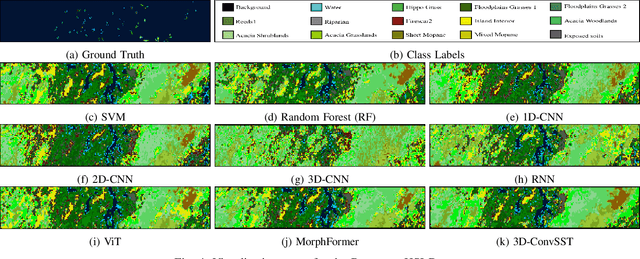
In recent years, Vision Transformers (ViTs) have shown promising classification performance over Convolutional Neural Networks (CNNs) due to their self-attention mechanism. Many researchers have incorporated ViTs for Hyperspectral Image (HSI) classification. HSIs are characterised by narrow contiguous spectral bands, providing rich spectral data. Although ViTs excel with sequential data, they cannot extract spectral-spatial information like CNNs. Furthermore, to have high classification performance, there should be a strong interaction between the HSI token and the class (CLS) token. To solve these issues, we propose a 3D-Convolution guided Spectral-Spatial Transformer (3D-ConvSST) for HSI classification that utilizes a 3D-Convolution Guided Residual Module (CGRM) in-between encoders to "fuse" the local spatial and spectral information and to enhance the feature propagation. Furthermore, we forego the class token and instead apply Global Average Pooling, which effectively encodes more discriminative and pertinent high-level features for classification. Extensive experiments have been conducted on three public HSI datasets to show the superiority of the proposed model over state-of-the-art traditional, convolutional, and Transformer models. The code is available at https://github.com/ShyamVarahagiri/3D-ConvSST.