 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Audio-Visual Segmentation
Paper and Code
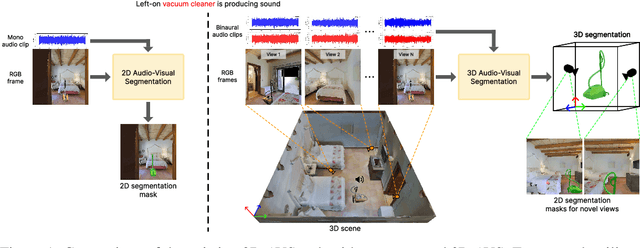

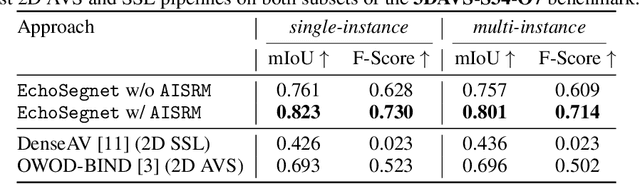
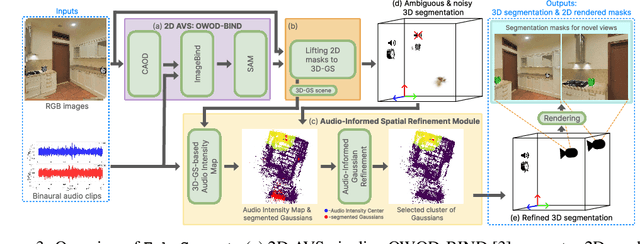
Recognizing the sounding objects in scenes is a longstanding objective in embodied AI, with diverse applications in robotics and AR/VR/MR. To that end, Audio-Visual Segmentation (AVS), taking as condition an audio signal to identify the masks of the target sounding objects in an input image with synchronous camera and microphone sensors, has been recently advanced. However, this paradigm is still insufficient for real-world operation, as the mapping from 2D images to 3D scenes is missing. To address this fundamental limitation, we introduce a novel research problem, 3D Audio-Visual Segmentation, extending the existing AVS to the 3D output space. This problem poses more challenges due to variations in camera extrinsics, audio scattering, occlusions, and diverse acoustics across sounding object categories. To facilitate this research, we create the very first simulation based benchmark, 3DAVS-S34-O7, providing photorealistic 3D scene environments with grounded spatial audio under single-instance and multi-instance settings, across 34 scenes and 7 object categories. This is made possible by re-purposing the Habitat simulator to generate comprehensive annotations of sounding object locations and corresponding 3D masks. Subsequently, we propose a new approach, EchoSegnet, characterized by integrating the ready-to-use knowledge from pretrained 2D audio-visual foundation models synergistically with 3D visual scene representation through spatial audio-aware mask alignment and refinement. Extensive experiments demonstrate that EchoSegnet can effectively segment sounding objects in 3D space on our new benchmark, representing a significant advancement in the field of embodied AI. Project page: https://surrey-uplab.github.io/research/3d-audio-visual-segmentation/