 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Long-term Dependent and Trustworthy Approach to Reactor Accident Prognosis based on Temporal Fusion Transformer
Oct 28, 2022



Prognosis of the reactor accident is a crucial way to ensure appropriate strategies are adopted to avoid radioactive releases. However, there is very limited research in the field of nuclear industry. In this paper, we propose a method for accident prognosis based on the Temporal Fusion Transformer (TFT) model with multi-headed self-attention and gating mechanisms. The method utilizes multiple covariates to improve prediction accuracy on the one hand, and quantile regression methods for uncertainty assessment on the other. The method proposed in this paper is applied to the prognosis after loss of coolant accidents (LOCAs) in HPR1000 reactor. Extensive experimental results show that the method surpasses novel deep learning-based prediction methods in terms of prediction accuracy and confidence. Furthermore, the interference experiments with different signal-to-noise ratios and the ablation experiments for static covariates further illustrate that the robustness comes from the ability to extract the features of static and historical covariates. In summary, this work for the first time applies the novel composite deep learning model TFT to the prognosis of key parameters after a reactor accident, and makes a positive contribution to the establishment of a more intelligent and staff-light maintenance method for reactor systems.
Representation Learning based and Interpretable Reactor System Diagnosis Using Denoising Padded Autoencoder
Aug 30, 2022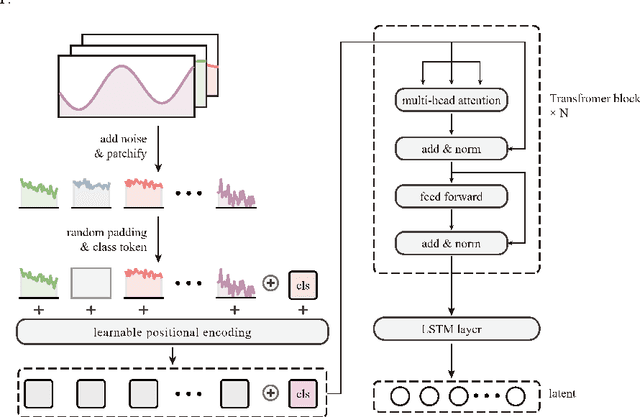

With the mass construction of Gen III nuclear reactors, it is a popular trend to use deep learning (DL) techniques for fast and effective diagnosis of possible accidents. To overcome the common problems of previous work in diagnosing reactor accidents using deep learning theory, this paper proposes a diagnostic process that ensures robustness to noisy and crippled data and is interpretable. First, a novel Denoising Padded Autoencoder (DPAE) is proposed for representation extraction of monitoring data, with representation extractor still effective on disturbed data with signal-to-noise ratios up to 25.0 and monitoring data missing up to 40.0%. Secondly, a diagnostic framework using DPAE encoder for extraction of representations followed by shallow statistical learning algorithms is proposed, and such stepwise diagnostic approach is tested on disturbed datasets with 41.8% and 80.8% higher classification and regression task evaluation metrics, in comparison with the end-to-end diagnostic approaches. Finally, a hierarchical interpretation algorithm using SHAP and feature ablation is presented to analyze the importance of the input monitoring parameters and validate the effectiveness of the high importance parameters. The outcomes of this study provide a referential method for building robust and interpretable intelligent reactor anomaly diagnosis systems in scenarios with high safety requirements.
An Unsupervised Learning-based Framework for Effective Representation Extraction of Reactor Accidents
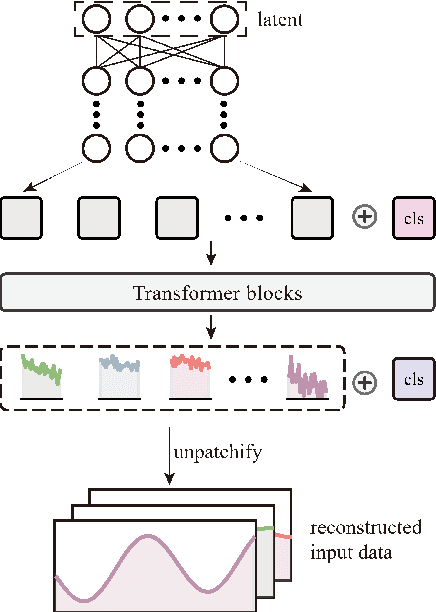
Aug 28, 2022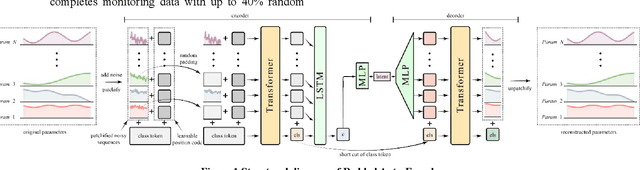
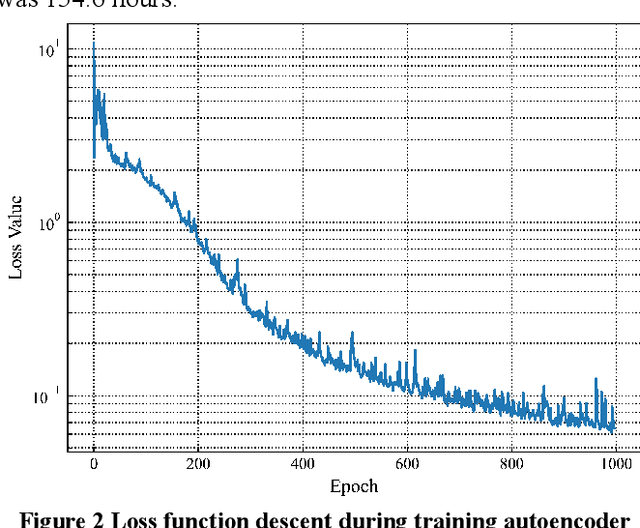
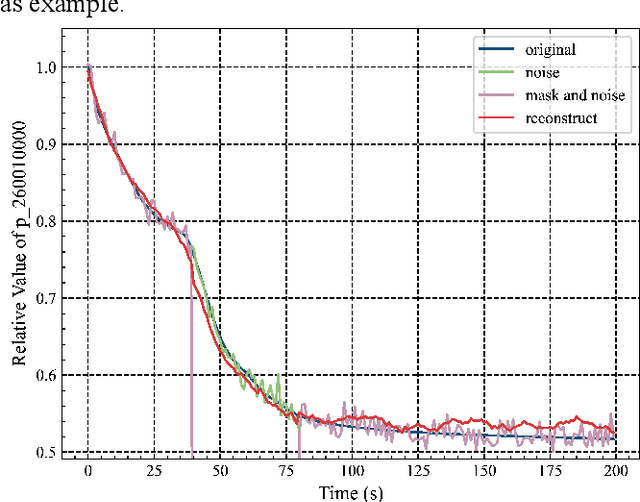
With the increasing use of high-precision system analysis programs in nuclear engineering, the number of high-fidelity computational data for accident simulation is exploding. Therefore, an algorithm that can achieve both automatic extraction of low-dimensional features from the data and guarantee the validity of the features is needed to improve the performance and confidence of the accident diagnosis system. This study proposes an autoencoder-based autonomous learning framework, namely Padded Auto-Encoder (PAE), which is able to automatically encode accident monitoring data that has been noise-added and with partially missing data into low-dimensional feature vectors via a Vision Transformer-based encoder, and to decode the feature vectors into noise-free and complete reconstructed monitoring data. Thus, the encoder part of the framework is able to automatically infer valid representations from partially missing and noisy monitoring data that reflect the complete and noise-free original data, and the representation vectors can be used for downstream tasks for accident diagnosis or else. In this paper, LOCA of HPR1000 was used as the study object, and the PAE was trained by an unsupervised method using cases with different break locations and sizes as the dataset. The encoder part of the pre-trained PAE was subsequently used as the feature extractor for the monitoring data, and several basic statistical learning algorithms for predicting the break locations and sizes. The results of the study show that the pre-trained diagnostic model with two stages has a better performance in break location and size diagnostic capability with an improvement of 41.62% and 80.86% in the metrics respectively, compared to the diagnostic model with end-to-end model structure.
Post-hoc Interpretability based Parameter Selection for Data Oriented Nuclear Reactor Accident Diagnosis System
Aug 03, 2022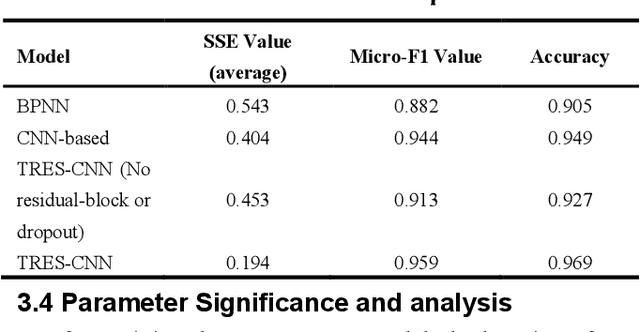



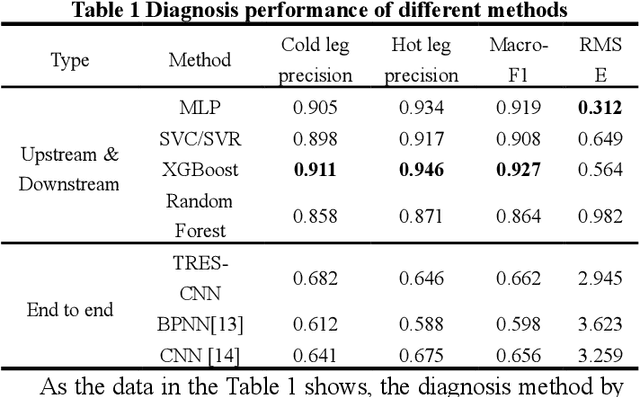
During applying data-oriented diagnosis systems to distinguishing the type of and evaluating the severity of nuclear power plant initial events, it is of vital importance to decide which parameters to be used as the system input. However, although several diagnosis systems have already achieved acceptable performance in diagnosis precision and speed, hardly have the researchers discussed the method of monitoring point choosing and its layout. For this reason, redundant measuring data are used to train the diagnostic model, leading to high uncertainty of the classification, extra training time consumption, and higher probability of overfitting while training. In this study, a method of choosing thermal hydraulics parameters of a nuclear power plant is proposed, using the theory of post-hoc interpretability theory in deep learning. At the start, a novel Time-sequential Residual Convolutional Neural Network (TRES-CNN) diagnosis model is introduced to identify the position and hydrodynamic diameter of breaks in LOCA, using 38 parameters manually chosen on HPR1000 empirically. Afterwards, post-hoc interpretability methods are applied to evaluate the attributions of diagnosis model's outputs, deciding which 15 parameters to be more decisive in diagnosing LOCA details. The results show that the TRES-CNN based diagnostic model successfully predicts the position and size of breaks in LOCA via selected 15 parameters of HPR1000, with 25% of time consumption while training the model compared the process using total 38 parameters. In addition, the relative diagnostic accuracy error is within 1.5 percent compared with the model using parameters chosen empirically, which can be regarded as the same amount of diagnostic reliability.