 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Enhanced Mobile Manipulation for Efficient Object Search in Indoor Environments
Aug 28, 2025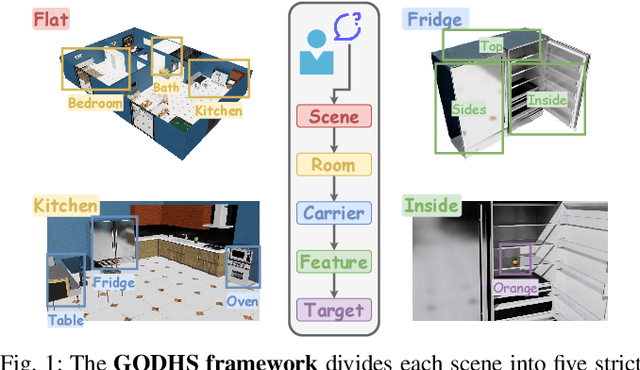
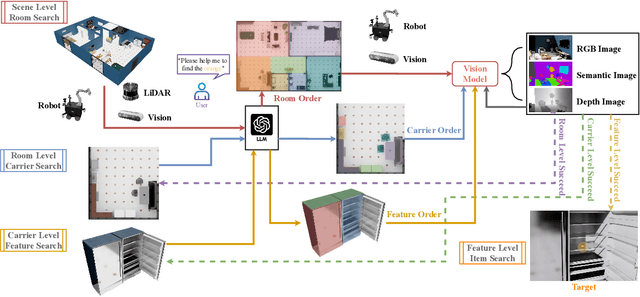
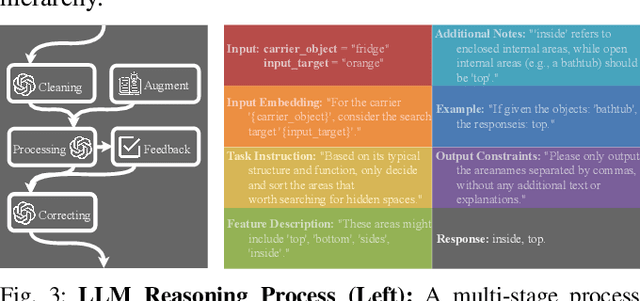

Enabling robots to efficiently search for and identify objects in complex, unstructured environments is critical for diverse applications ranging from household assistance to industrial automation. However, traditional scene representations typically capture only static semantics and lack interpretable contextual reasoning, limiting their ability to guide object search in completely unfamiliar settings. To address this challenge, we propose a language-enhanced hierarchical navigation framework that tightly integrates semantic perception and spatial reasoning. Our method, Goal-Oriented Dynamically Heuristic-Guided Hierarchical Search (GODHS), leverages large language models (LLMs) to infer scene semantics and guide the search process through a multi-level decision hierarchy. Reliability in reasoning is achieved through the use of structured prompts and logical constraints applied at each stage of the hierarchy. For the specific challenges of mobile manipulation, we introduce a heuristic-based motion planner that combines polar angle sorting with distance prioritization to efficiently generate exploration paths. Comprehensive evaluations in Isaac Sim demonstrate the feasibility of our framework, showing that GODHS can locate target objects with higher search efficiency compared to conventional, non-semantic search strategies. Website and Video are available at: https://drapandiger.github.io/GODHS
Semantic Relation Preserving Knowledge Distillation for Image-to-Image Translation
May 19, 2021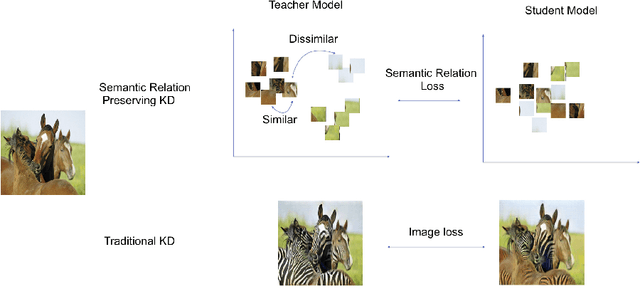
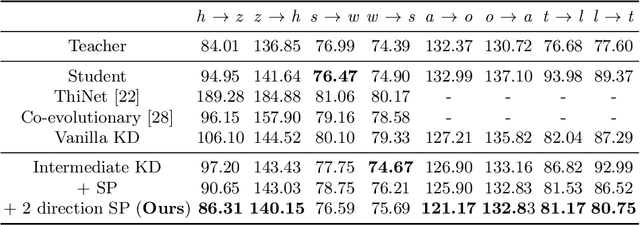
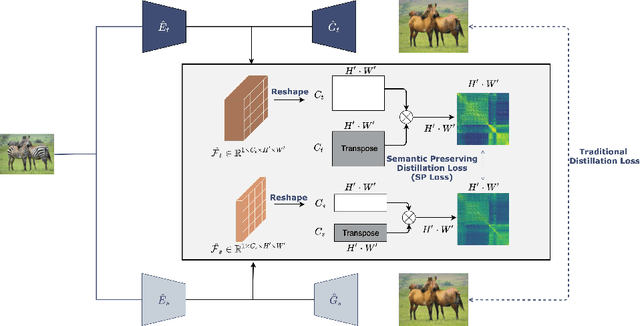
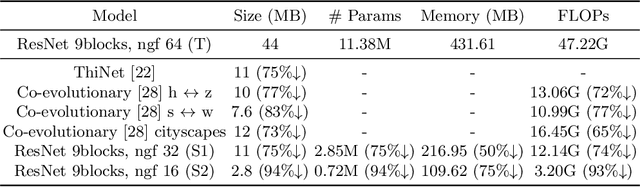
Generative adversarial networks (GANs) have shown significant potential in modeling high dimensional distributions of image data, especially on image-to-image translation tasks. However, due to the complexity of these tasks, state-of-the-art models often contain a tremendous amount of parameters, which results in large model size and long inference time. In this work, we propose a novel method to address this problem by applying knowledge distillation together with distillation of a semantic relation preserving matrix. This matrix, derived from the teacher's feature encoding, helps the student model learn better semantic relations. In contrast to existing compression methods designed for classification tasks, our proposed method adapts well to the image-to-image translation task on GANs. Experiments conducted on 5 different datasets and 3 different pairs of teacher and student models provide strong evidence that our methods achieve impressive results both qualitatively and quantitatively.
Continuous Face Aging via Self-estimated Residual Age Embedding
Apr 30, 2021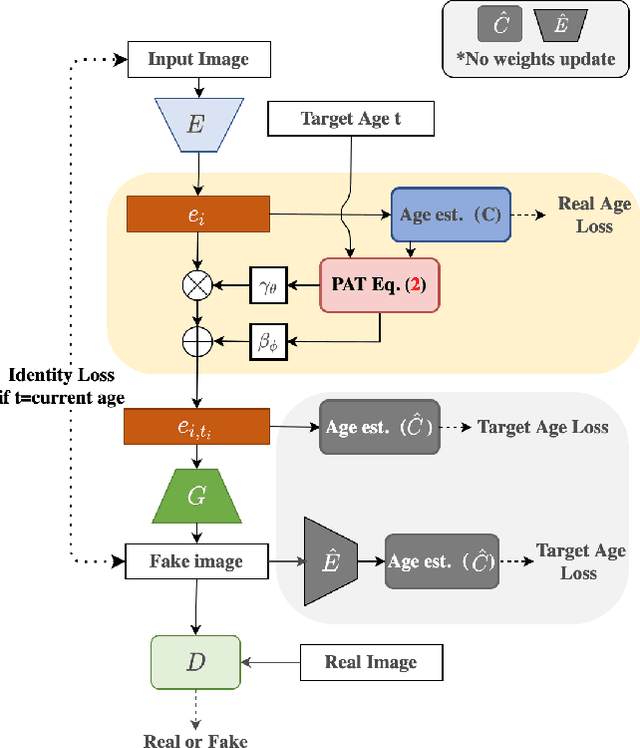
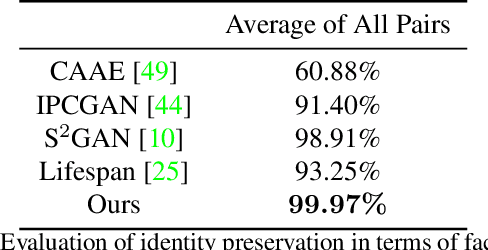


Face synthesis, including face aging, in particular, has been one of the major topics that witnessed a substantial improvement in image fidelity by using generative adversarial networks (GANs). Most existing face aging approaches divide the dataset into several age groups and leverage group-based training strategies, which lacks the ability to provide fine-controlled continuous aging synthesis in nature. In this work, we propose a unified network structure that embeds a linear age estimator into a GAN-based model, where the embedded age estimator is trained jointly with the encoder and decoder to estimate the age of a face image and provide a personalized target age embedding for age progression/regression. The personalized target age embedding is synthesized by incorporating both personalized residual age embedding of the current age and exemplar-face aging basis of the target age, where all preceding aging bases are derived from the learned weights of the linear age estimator. This formulation brings the unified perspective of estimating the age and generating personalized aged face, where self-estimated age embeddings can be learned for every single age. The qualitative and quantitative evaluations on different datasets further demonstrate the significant improvement in the continuous face aging aspect over the state-of-the-art.