 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Recovery or Decease of COVID-19 Patients with Clinical and RT-PCR Using Machine Learning Classification Algorithms
Nov 23, 2023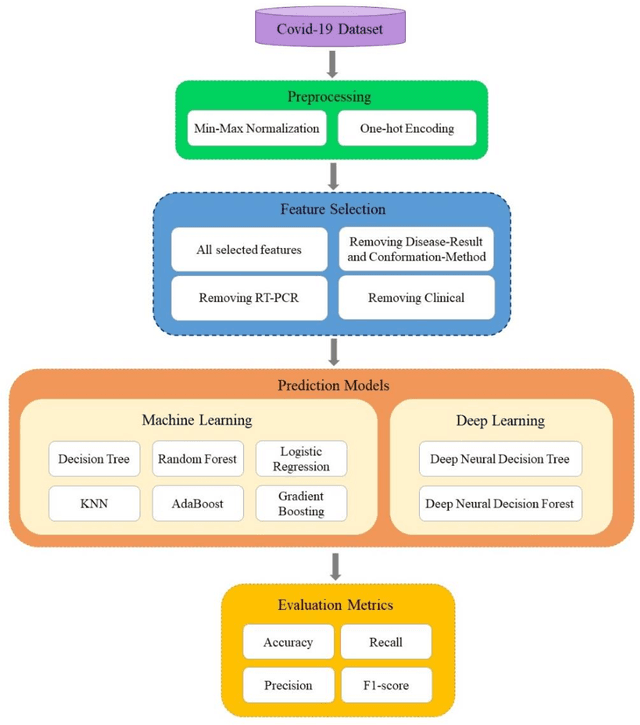
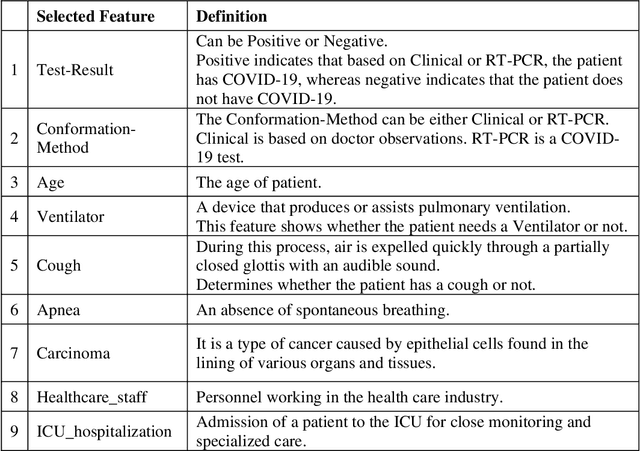
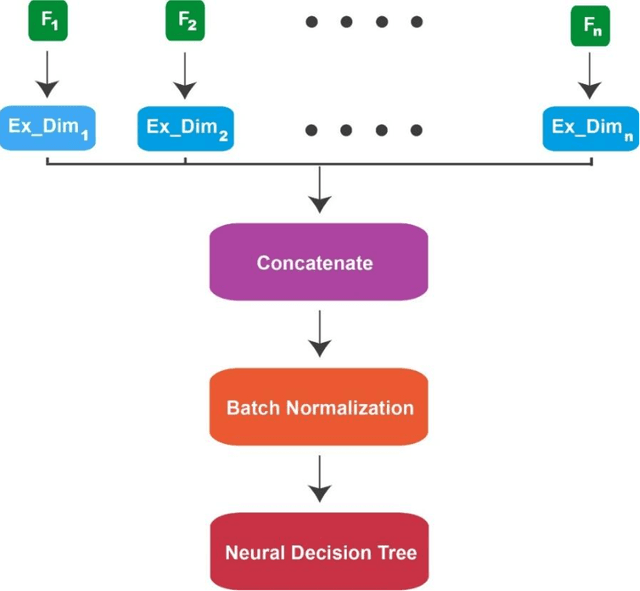
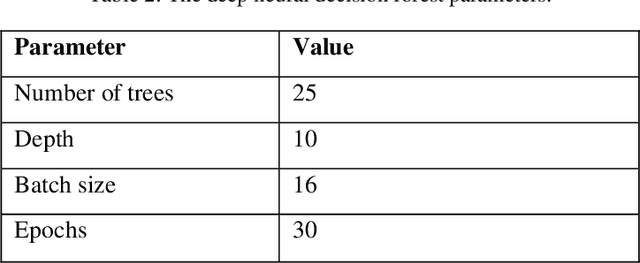
The COVID-19 pandemic has disrupted the global economy and people's daily lives in unprecedented ways. To make appropriate decisions, it is necessary to diagnose COVID-19 rapidly and accurately. Clinical decision making is influenced by data collected from patients. With the aid of artificial intelligence, COVID-19 has been diagnosed quickly by analyzing symptoms, polymerase chain reaction (PCR), computed tomography scans, chest X-rays, routine laboratory blood tests and even cough sounds. Furthermore, these data can be used to predict a patient's morality, although there is a question about which data makes the most accurate predictions. Therefore, this study consists of two parts. Our first objective is to examine whether machine learning algorithms can predict the outcome of COVID-19 cases (recovery or death), based on the features present in the dataset. In the second part of the research, we investigated the impact of clinical and RT-PCR on prediction of recovery and decease to determine which one is more reliable. We defined four stages with different feature sets and use six machine learning methods to build prediction model. With an accuracy of 78.7%, random forest showed promising results for predicting death and recovery of patients. Based on this, it appears that recovery and decease of patients are predictable using machine learning. For second objective, results indicate that clinical alone (without using RT-PCR), trained with AdaBoost algorithm, is the most accurate with an accuracy of 82.1%. This study can provide guidance for medical professionals in the event of a crisis or outbreak similar to COVID-19.
Discovering the Symptom Patterns of COVID-19 from Recovered and Deceased Patients Using Apriori Association Rule Mining
Aug 13, 2023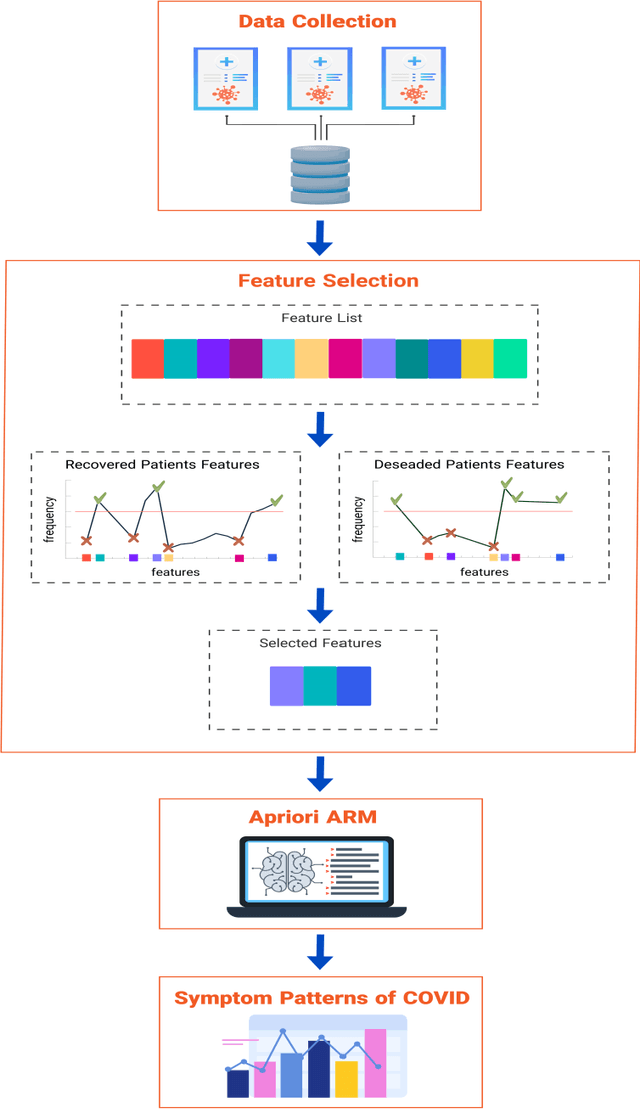



The COVID-19 pandemic has a devastating impact globally, claiming millions of lives and causing significant social and economic disruptions. In order to optimize decision-making and allocate limited resources, it is essential to identify COVID-19 symptoms and determine the severity of each case. Machine learning algorithms offer a potent tool in the medical field, particularly in mining clinical datasets for useful information and guiding scientific decisions. Association rule mining is a machine learning technique for extracting hidden patterns from data. This paper presents an application of association rule mining based Apriori algorithm to discover symptom patterns from COVID-19 patients. The study, using 2875 records of patient, identified the most common symptoms as apnea (72%), cough (64%), fever (59%), weakness (18%), myalgia (14.5%), and sore throat (12%). The proposed method provides clinicians with valuable insight into disease that can assist them in managing and treating it effectively.
BioBERT Based SNP-traits Associations Extraction from Biomedical Literature
Aug 03, 2023



Scientific literature contains a considerable amount of information that provides an excellent opportunity for developing text mining methods to extract biomedical relationships. An important type of information is the relationship between singular nucleotide polymorphisms (SNP) and traits. In this paper, we present a BioBERT-GRU method to identify SNP- traits associations. Based on the evaluation of our method on the SNPPhenA dataset, it is concluded that this new method performs better than previous machine learning and deep learning based methods. BioBERT-GRU achieved the result a precision of 0.883, recall of 0.882 and F1-score of 0.881.
Political Sentiment Analysis of Persian Tweets Using CNN-LSTM Model
Jul 15, 2023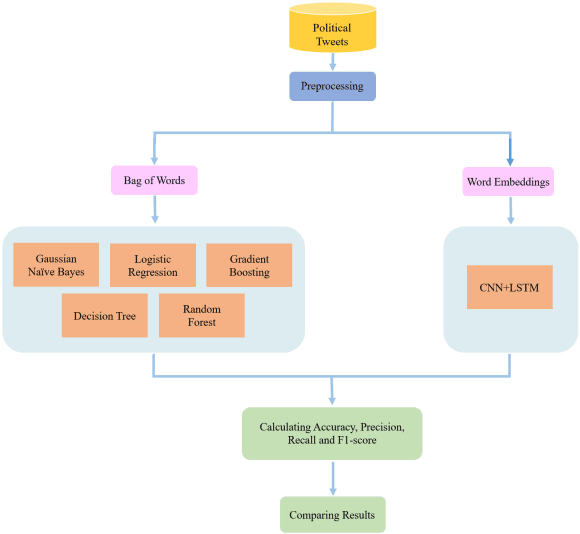
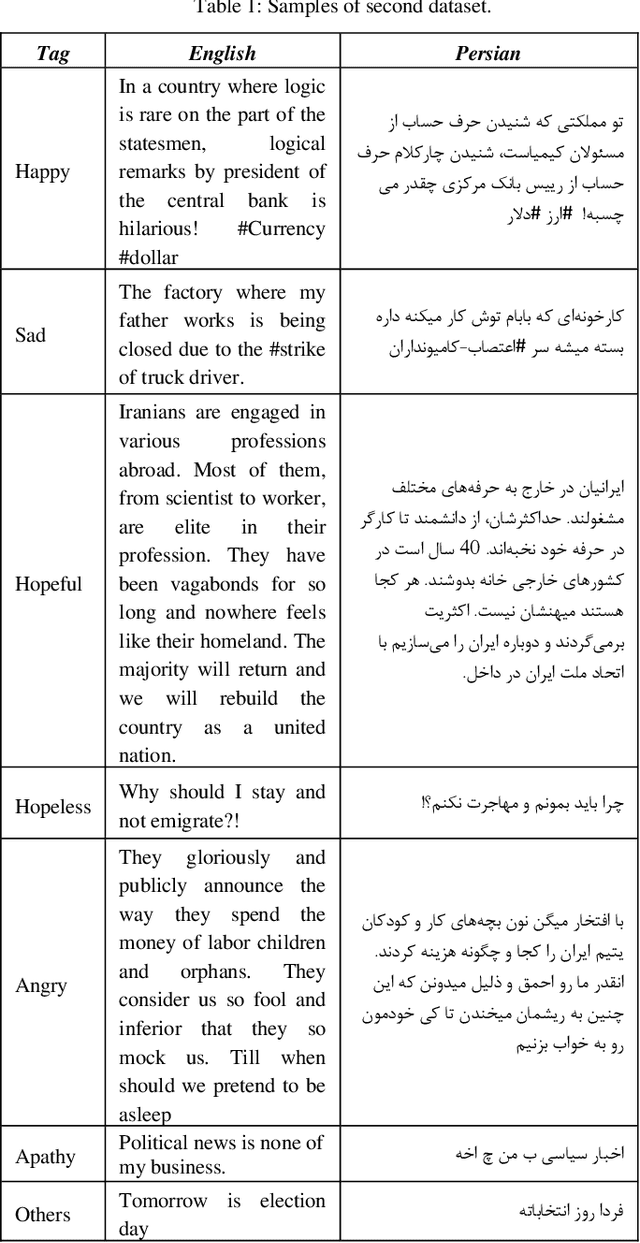
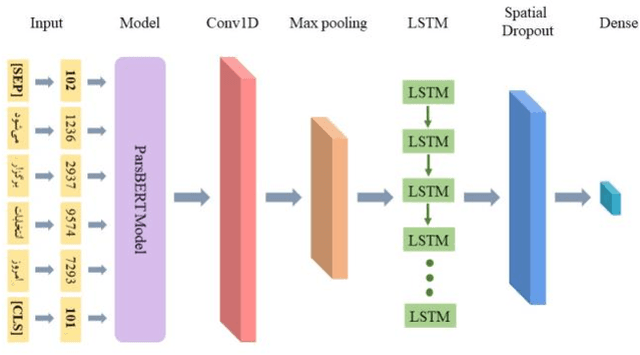
Sentiment analysis is the process of identifying and categorizing people's emotions or opinions regarding various topics. The analysis of Twitter sentiment has become an increasingly popular topic in recent years. In this paper, we present several machine learning and a deep learning model to analysis sentiment of Persian political tweets. Our analysis was conducted using Bag of Words and ParsBERT for word representation. We applied Gaussian Naive Bayes, Gradient Boosting, Logistic Regression, Decision Trees, Random Forests, as well as a combination of CNN and LSTM to classify the polarities of tweets. The results of this study indicate that deep learning with ParsBERT embedding performs better than machine learning. The CNN-LSTM model had the highest classification accuracy with 89 percent on the first dataset with three classes and 71 percent on the second dataset with seven classes. Due to the complexity of Persian, it was a difficult task to achieve this level of efficiency.
A Survey From Distributed Machine Learning to Distributed Deep Learning
Jul 11, 2023Artificial intelligence has achieved significant success in handling complex tasks in recent years. This success is due to advances in machine learning algorithms and hardware acceleration. In order to obtain more accurate results and solve more complex problems, algorithms must be trained with more data. This huge amount of data could be time-consuming to process and require a great deal of computation. This solution could be achieved by distributing the data and algorithm across several machines, which is known as distributed machine learning. There has been considerable effort put into distributed machine learning algorithms, and different methods have been proposed so far. In this article, we present a comprehensive summary of the current state-of-the-art in the field through the review of these algorithms. We divide this algorithms in classification and clustering (traditional machine learning), deep learning and deep reinforcement learning groups. Distributed deep learning has gained more attention in recent years and most of studies worked on this algorithms. As a result, most of the articles we discussed here belong to this category. Based on our investigation of algorithms, we highlight limitations that should be addressed in future research.