 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVI-SAC: Average Reward Off-Policy Deep Reinforcement Learning
Aug 04, 2024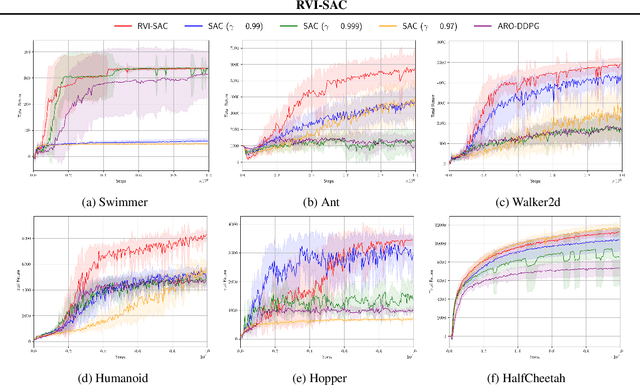
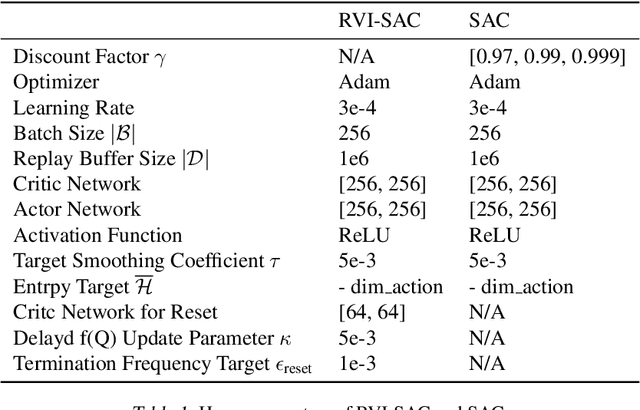
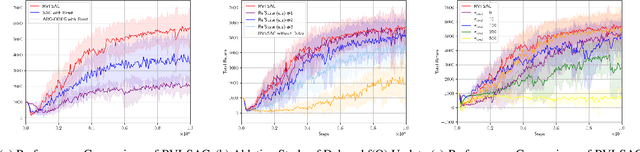
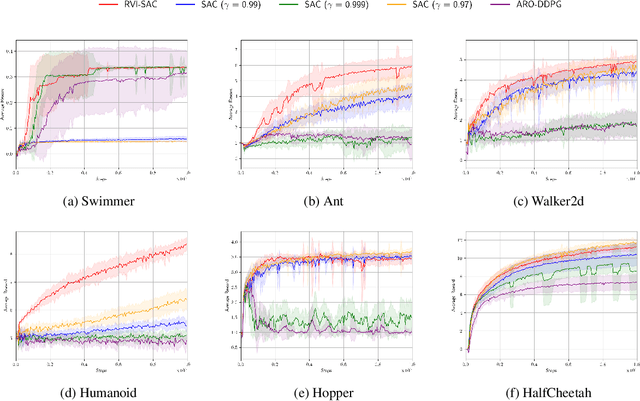
In this paper, we propose an off-policy deep reinforcement learning (DRL) method utilizing the average reward criterion. While most existing DRL methods employ the discounted reward criterion, this can potentially lead to a discrepancy between the training objective and performance metrics in continuing tasks, making the average reward criterion a recommended alternative. We introduce RVI-SAC, an extension of the state-of-the-art off-policy DRL method, Soft Actor-Critic (SAC), to the average reward criterion. Our proposal consists of (1) Critic updates based on RVI Q-learning, (2) Actor updates introduced by the average reward soft policy improvement theorem, and (3) automatic adjustment of Reset Cost enabling the average reward reinforcement learning to be applied to tasks with termination. We apply our method to the Gymnasium's Mujoco tasks, a subset of locomotion tasks, and demonstrate that RVI-SAC shows competitive performance compared to existing methods.